Master's thesis
May 22, 1995
Marko Turpeinen
Helsinki University of Technology
Laboratory of Information Processing Science
This thesis[1] is part of the OtaOnline research project at the Helsinki University of Technology. I would like to take this opportunity to thank all those who have contributed to this work, directly or indirectly.
I would first like to express my gratitude to my adviser Prof. Shosta Sulonen for his constructive criticism, guidance, support and for sharing his wealth of knowledge, all of which have had a strong influence on this thesis.
I would like to thank my colleagues Mari Korkea-aho and Tuomas Puskala, for their help and comments on this work. I would also like to thank the Personal News Assistant project group, Marko Astikainen, Vesa Kautto, Jarkko Siitonen and Mikko Sirén, for their inspiring work well done.
I would like to thank Aamulehti Group and Technological Development Centre of Finland (TEKES) for providing financial support for the work in this thesis.
I am grateful to my parents and relatives for their encouragement and support without which I certainly would not have reached this far.
I would especially like to thank my wife, Hanna, for her immense patience and sacrifices that have made this work possible, and my children, Aleksi and Laura, for cheering me up when completing this work seemed like impossible.
Marko Turpeinen
mtu@cs.hut.fi
May 21, 1995
"Would you tell me, please, which way I ought to go from here?"
"That depends a good deal on where you want to get to," said the Cat
-- Lewis Carroll, Alice in Wonderland
In the recent years the concept of an intelligent agent has become important in both Artificial Intelligence (AI) and mainstream computer science. The aim of this thesis is to present a framework for agent-based personalised information services in multimedia contents.
There has been an intense growth of interest in the 1990s in heterogeneous, distributed information networks such as the Internet. The number of Internet users and the amount of information available is growing exponentially. As more and more people get connected to the network, the demand for personalised information services is increasing. Moreover, advances in network infrastructure, computer technology, and globally accepted standards, are about to make personalised multimedia services technically feasible.
Interactive systems will allow their users the flexibility of selecting and receiving specific information from the information marketplace. The rapid growth of available communication bandwidth and computing power are making it possible to process and deliver information on a per-user, per session basis in real-time.
The agent technology enables the information provider to extract relevant data about the consumers and modify their information contents to specific user tastes. Users of such services will have the flexibility in choosing the kinds of information they receive. They can also control, based on individual preferences, the manner and time of receipt of this information.
The aim of this study is to introduce the agent technology, information filtering, and personalised network services in the electronic market framework. An architecture for personalised agent-based services, and emerging tools for providing these applications, are presented.
The study is based on a review of related literature and other ongoing projects, interviews with other researchers, and early experimental work done within the OtaOnline project. The main purpose of this work is to understand the most important research problems in this domain, and to propose a research plan and experimental agent applications to be implemented.
The large size of multimedia objects, and the high number of simultaneous users, means that many of these multimedia services are not feasible in large scale with current technology. The requirements for network bandwidth, processing and I/O capacity, storage capacity, and software technology, are considerable. I do not attempt to propose a solution to solve these problems, but I have tried to take them into account in the service architecture and in the evaluation of possible applications of agent technology.
Multimedia services are composed of data objects. These objects should be modeled and stored in a database. Agents should have access to this database to get descriptors about the contents of the data objects available, and to get the actual data objects. Some issues concerning this data about data (i.e. metadata) are presented in this work, but the database framework to satisfy these needs is not specified.
The "on-demand" nature of personalised services requires the dynamic creation of multimedia presentations based on the material available. Some of the requirements and technical constraints involved are introduced from the system architecture point of view, but otherwise these problems are not considered in this work.
The emphasis in this thesis is on the information filtering applications involving agent-to-agent intercommunication. There are plenty of other possible agent application areas, such as workflow management, adaptive user interfaces, simulation, network management, but they are out of scope of this work.
This work is part of the OtaOnline project at the Helsinki University of Technology. In addition to personalisation, the research areas of the project cover instrumentation, scalability, as well as the production and consumption processes of distributed multimedia services.
In previous research work done at the Helsinki University of Technology agent technology has been used to sort and filter a stream of messages. These systems include PAGES, a system for computer supported co-operative work [Hämmäinen et al., 1990], and SyNews, a system for semi-structured messaging, which was part of the Synergy Exchange project.
During the semester 1994-95 I have been instructing a group of students on the "Software Project" course at the Helsinki University of Technology. The result of this work is a Personal News Assistant that employs agent technology to filter news items.
OtaOnline project is working in co-operation with the Media Laboratory of the Massachusetts Institute of Technology (MIT Media Lab), where the personalised information services have been extensively studied. The current projects at MIT include [MIT, 1995]:
* FishWrap - an experimental, on-demand, self-organising, electronic newspaper, where students build their customised news presentation from a large pool of information sorted by topical and geographical interests
* Doppelgänger - a user-modeling system for dynamically controlling the full computational environment of the user
* News Games - different approach to access news content, where the goal is to entertain while engaging the player in the editorial and advertising content
* Understanding News - memory-based representation systems are being applied to comprehending, filtering, and summarising news stories
* Interface Agents - AI techniques applied to the field of human-computer interaction, where the interface is more adaptive, more intelligent, and personalised
* Personal Editors and Critics - attempt to deal with information and entertainment overload by using agents that make personalised suggestions to a user
There is also a wide range of other agent-related research and implemented systems that use agent technology. The Internet is an excellent source for more information[2].
Chapter two describes the multimedia service concept from the electronic marketplace perspective. Chapter three introduces the intelligent agents, and some possibilities in using agent technology. Chapter four is dedicated to specifying the possible dimensions of personalisation in multimedia services and it also covers different methods for information filtering. Examples of agent-based approaches to information filtering are introduced.
Chapter five presents the personalised multimedia service architecture, and introduces the main components of the architecture in detail. The biggest problems in implementing these services are introduced.
Chapter six covers the emerging tools for providing agent-oriented software. The recommendations for future work are presented in chapter seven and the results of this work are summarised in chapter eight.
Marshall McLuhan considers media as "extensions to man", as technologies and products giving our senses access to further forms of information [McLuhan, 1964]. The term media has two uses: it relates to how information is conveyed and distributed, but also to the materials and different forms of artistic expression (audio, video, text, animation, etc.).
Media data means the representations of machine-readable objects produced in a particular medium. We can define multimedia as the composition and simultaneous use of data objects in different media forms [Koegel Buford, 1994, Gibbs & Tsichtitzis, 1995].
Hypertext is a non-linear collection of linked items of text or other data objects. If the focus of such a system is on non-textual, multimedia information, the term hypermedia is used instead.
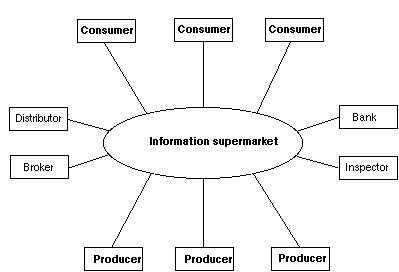
A global information network, such as Internet, can be considered as a very large electronic marketplace where consumers search for information and services. The consumer wants to maximise the number of different alternative services considered and the ease of comparing them.
Producers, i.e. information content and service providers, are actively looking for interested customers. The producer is motivated to have consumers purchase his products rather than those of his competitors, and he wishes to establish electronic interconnections with his customers.
The electronic market can also include various levels of "middlemen", who act as distributors or brokers in the transfer of goods and services. In addition, there may be various kinds of financial service firms such as banks and credit card issuers, who store, transfer, and loan the funds involved in transactions. An inspector company assures the quality of information, goods, or services provided by producers.
Figure 1. The information marketplace
A broker can act as a middle layer between parties of the trade, especially when the direct negotiation between producers and consumers is undesirable, for one or more of the following reasons [Resnick, 1995]:
* Search costs. It may be expensive for producers and the consumers to find each other. A broker can match the potential customers and suppliers in the market, and thus reduce the need for consumers and producers to contact a large number of alternative partners.
* Lack of privacy. Either buyer or seller might want to remain anonymous in the trade. A broker can offer name translation service to relay messages without revealing the identity different trading parties.
* Incomplete information. The buyer may need more information about the product than the seller is able or willing to provide. A broker can gather independent product descriptions and assessments from other sources than the producer.
* Contracting risks. The producer may refuse to service a defective product. Similarly the consumer may refuse to pay after receiving the product. A broker can share information about the behaviour of producers and consumers to discourage bad behaviour.
* Pricing inefficiencies. In trying to secure a desirable price for a product, producers and consumers may miss opportunities for desirable exchanges. This is especially true for custom products that have only one buyer and seller. A broker can improve the efficiency of pricing.
To a large extent, these brokering functions can be implemented electronically as agent-based services. Thus the electronic brokerage effect can increase the number of alternatives to be considered, increase the quality of the alternatives eventually selected, and decrease the cost of entire selection process [Malone, 1987, p.488].
The structure of the new global information industry is about the change the information service production, distribution and consumption processes. The key players in the information services market are the information content producers and the electronics industry: computing, consumer electronics, telecommunications [Commission of the European Communities, 1993].
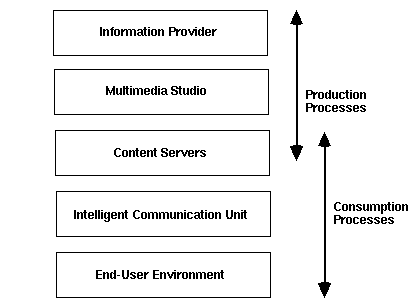
The consumption and production processes in multimedia services are modeled in the figure 2. Different information providers (TV, radio, publishers, etc.) produce contents in different forms of digital media. The data objects are collected in production databases in device independent format. These databases are accessible by multimedia studios, where the data objects are linked to create a hypermedia product. The material is made available to the users by content servers. These servers have access to the multimedia products that are stored in multimedia archives as object collections. The end-user requests are directed to a request engine, that serves the multimedia objects to the users. The request engine has to scale up to support many and large multimedia objects, and a large user community.
The consumer has an end-user environment including a display device, connection device that has capacity for local memory and processing, incoming and outgoing network bandwidth, and some interaction device (keyboard, remote control device, mouse, or voice commands). The consumer connects to the intelligent communication unit, that enables the use of different underlying communications media: cable, satellite, high-speed packet-switched networks, etc. They have the capacity for information buffering and caching on a per-user basis.
The publishing industry is possibly the most potential multimedia service producer. Early experience from the OtaOnline project shows that the online multimedia publishing will require entirely new skills and changes in the current production process to provide attractive content to the new media. The lack of personnel skilled in developing, designing and manufacturing multimedia products is one of the severest barriers to successful new media publishing.
Three stages can be identified in the electronic market evolution: biased, unbiased, and personalised stage. In biased markets the producer attempts to capture customers in systems biased toward that particular producer. There are significant benefits for the customers to have open unbiased services. In the long run, the electronic brokerage effect will drive electronic markets toward being unbiased channels for services from many providers [Malone, 1987b, p.492].
Example: Airline reservation systems [Malone, 1987b, p.492]
American Airlines (AA) and United Airlines (UA) introduced reservation systems allowing travel agents to find and book flights, print tickets, and so forth. UA provided initially a system where only tickets from UA could be booked. To compete with this system, AA introduced their system that included flights from all airlines, but with AA flights for a given route listed first. UA soon adopted the same strategy, and soon two thirds of all bookings where done through either of these systems. This significant bias towards UA and AA led other airlines to protest, and finally rules from Civil Aeronautics Board eliminated most of the bias in reservation systems.
In unbiased electronic markets the users can be overwhelmed with more alternatives they can possibly consider. This problem is especially relevant, if the product descriptions are not standardised and can be valued very differently by different consumers. This is the case in the multimedia service markets.
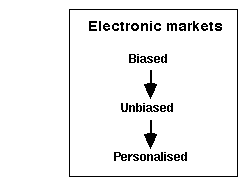
Figure 3. Evolution of electronic markets [Malone, 1987b, p.490]
The personalised electronic markets will provide intelligent decision aids to help individual customers select from the alternatives available and act as automated agents for the consumers. These agents filter the most interesting information and services to the user according to user's preferences. These preference rules can also be made available to producers, which would increase the efficiency of the markets. The producers can get dynamic feedback about the changes in the markets by observing the user preferences.
The evolution of online services has mirrored the trends in general computing technology, from host-based systems to client/server architecture, and from character-based to graphical user interface. Currently third, agent-based generation, is beginning to emerge.
In first-generation services, information came from the host, and all the processing was done there except local character-based screen rendering and locally maintained address-books, message folders, and downloaded files.
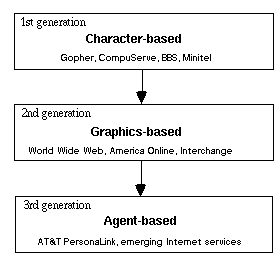
Figure 4. Three generations of online services [Reinhardt, 1994, p.56 ]
The second-generation services introduced primitives for standard graphics-based presentation and hyperlinking. The client was presumed to have more processing power and a faster connection to the network. Graphics-based interface to the World-Wide Web (NCSA Mosaic, Netscape) has been one of the main reasons for extremely rapid growth of Internet in the 1993-95.
The figure 5 shows the growth of the World-Wide Web. The traffic in the main Internet backbone network, NSFNET[3], has been measured by service. Services mentioned are WWW, z.39.50[4], and Gopher. The byte count is measured in terabytes (1 TB = 1012 B). The reduction of traffic in January 1995 is due to the commercialisation of the Internet backbone traffic. The U.S. government-funded NSFNET will not be one of the major carriers of Internet traffic in the future.
Agent-based third generation services introduce flexible, distributed, and modular technologies, that enable handling of increasing complexity of network environments. Agents make intelligent personalised services feasible.
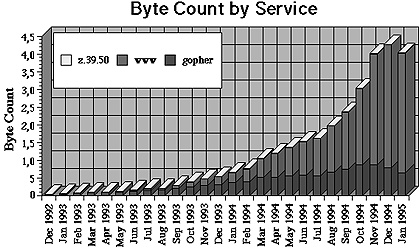
Figure 5. The growth of the World-Wide Web [Pitkow, 1995]
For any market, it is important to estimate the number of potential consumers. Here we can use the Internet as an example of an electronic marketplace. How many people use the Internet? The question is impossible to answer accurately, since the Internet does not have any central control. A survey done in October '94 estimated the size of the Internet to be 13.5 million active users world-wide [Matrix, 1994].
Table 1. The size of the Internet in October 1994
Category Users (people) Hosts (computers) Core Internet potential 7.8 million 2.5 million service providers Consumer Internet information 13.5 million 3.5 million service users Matrix electronic mail access 27.5 million -
The categories in table 1 fit inside each other: the Matrix (mail exchange Internet) includes the Consumer Internet, which includes the Core Internet. According to this survey the number of active Internet users, who can provide interactive services such as Telnet, FTP or WWW, is currently higher (7.8 million) than the users that can only consume these services (5.7 million). We can expect to see a rapid growth in the consumer Internet as the number of commercial Internet access providers increases.
 1985 1990 1995
1985 1990 1995
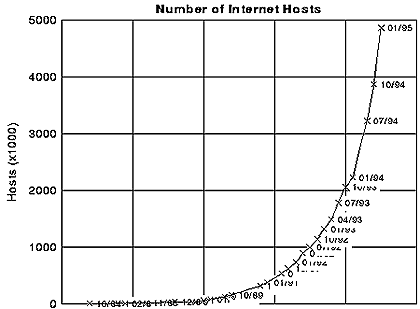
The exact size of the Internet can only be estimated. However, many different measurements have indicated that the Internet is growing exponentially, approximately doubling in size each year, and has been doing so for at least the past six years now. This exponential growth is clearly visible in the number of Internet hosts in figure 6.
Equally important question for the content producers that are planning to charge for their information services is the willingness of people to pay for the information services available through the Internet. A recent survey done in the U.S.A. showed that 80 % of the users of the WWW would be willing to pay for the services they get [Hermes, 1994]. Current growth of the Internet indicates a rapidly growing demand for interactive network services.
In the traditional push or broadcast mode of information services, typified by cable television, consumers can neither control the programs they view nor schedule the viewing time of programs to suit their preferences. To view programs of interest, consumers must subscribe to all the channels that broadcast at least one such program. Thus, consumers face an overload of irrelevant information at additional cost. In contrast, the pull or on-demand mode permits clients to procure only what they desire, schedule the viewing times of programs, and control programs remotely. [Ramanathan & Rangan, 1994, p.37]
A multimedia system can either store multimedia objects to be used later by an application such as video-on-demand, or transmit them in real time. Live audio and video can be interactive, such as multimedia conferencing, or noninteractive, as in traditional TV broadcasting.
Interactive services represent a fundamental change in the TV channel delivery paradigm: multiple simultaneous parallel streams (channels) are replaced by large number of concurrent accesses via separate channels into a database. The restriction of parallel and competing programs will no longer be valid, since all programming becomes available any time to the user.
Interactive multimedia requires enormous network bandwidth. The existing network infrastructure, such as Ethernet and Internet protocols (CSMA/CD, TCP/IP), is not able to support the high bandwidth, low-latency requirements of audio and video data. If ten million people watch fully personalised entertainment-quality video programming, the bandwidth required is 107 * 6 Mb/s = 60 Tb/s. Thus, the required bandwidth per second is about the same as the current WWW backbone traffic in the U.S.A. in one month. It will clearly take some time until the network infrastructure can support these requirements.
Table 2. Bandwidth and storage requirements for different data types
Data type Object type Size and Storage requirements
bandwidth (1 GB can store)
Text ASCII 2 kB/ page 500 000 pages
Image Low-resolution 64 kB/ image 15 625 images
compressed bitmap
Image High-resolution 4 MB/ image 250 images
compressed bitmap
Audio Phone quality 128 kb/s 17,4 hours
8kHz / 8 bits
(mono)
Audio CD quality 44kHz / 1,4 Mb/s 1,6 hours
16 bits
Animation Synchronised image 1,3 Mb/s 1,7 hours
at 640x320x16 (compression
pixel 16 frames / 15:1)
second
Video Digital MPEG-1 1,5 Mb/s 1,5 hours
320x240x24 pixel
30 frames / second
Video Digital MPEG-2 6 Mb/s 22 min
720x480x24 pixel
30 frames / second
Processing, storage and memory requirements include very high capacity, fast access times, efficient I/O and high transfer rates [Fuhrt, 1994, p.47]. Development of interactive multimedia services requires solving a diverse set of other problems (end-user equipment, network access technologies, storage servers, multimedia databases, information security, user interface design, billing for services, copyright issues, etc.). While most of the recent media attention has focused on what information services should be delivered, there has been little said about how these systems will be assembled and what they should cost. The big questions in providing scalable interactive services are still to be solved.
Table 3. Interactive Multimedia Services
Application Description Personalisation Ease of Influence
imp-lementat potential
ion
Interactive Multimedia newscasts News material Network - Business +
multimedia with the ability to is selected Processing Home ++
news see more detail on according to - Storage -
selected stories. user interest Software +
Interactive profiles and
selection and tailored to
retrieval from customer's
hyperlinked material. needs.
Interactive Distributed virtual Virtual Network + Business -
multipartici reality games for personalities Processing Home +
-pant games online communities. and customised + Storage
role-games. ++ Software
+
Telecommerce Consumers purchase Personal offers Network + Business +
goods from the and Processing Home ++
electronic advertisements. + Storage +
marketplace. Software +
Distance Students can The courses can Network + Business +
learning subscribe to courses be tailored to Processing Home +
being taught at individual + Storage -
remote sites. preferences and Software -
time
constraints.
Multimedia Electronic messages Agent-based Network + Business +
mailing can contain audio, filtering, Processing Home +
video, graphics, and sorting and ++ Storage
other media. forwarding + Software
based on a user ++
profile.
Multimedia Shared virtual Distance Network - Business ++
conferencing workspace. working and Processing Home -
Participants can workgroups. + Storage
send and receive ++ Software
multimedia data. +
Entertainmen Consumer can select Customised Network - - Business -
t-on-demand and play audio and programming and Processing - Home ++
video material recommendations. - Storage -
(movies, sports, Full control on Software +
shows, music). the
presentation.
++
Available or easily feasible today/ High potential + Feasible in the next three
years/ Medium potential- Difficult to implement/ Low potential - - Very difficult to implement/ Not potential
Table 3 summarises some of the most potential distributed multimedia services and the possibilities for personalisation in their implementation. Some of these services, such as multimedia mailing, already exist today, some are totally new services.
The technological requirements are different for each service. Network bandwidth, CPU and I/O processing performance, storage requirements and application software are the most important technological constraints. The "Ease of implementation" column summarises my view on the large-scale technological feasibility of these services.
It is very difficult to estimate, which service will be the most influential in the future. I have expressed my view on the possible impact of these services in the "Influence potential" column, considering the business and home consumer markets separately. Other points of view, such as social implications of these services, are equally significant, but have not been considered in this analysis.
Intelligent agents are autonomous and adaptive computer programs operating within software environments such as operating systems, databases or computer networks. This technology combines artificial intelligence (reasoning, planning, learning, natural language processing) and system development techniques (object-oriented programming, scripting languages, human-machine interface, distributed processing) to produce a new generation of software that can, based on user preferences, perform tasks for users.
As the number of people using networked computing systems grows exponentially, and as these systems become ever more distributed, interconnected, and open, the intelligent agent technology has a significant potential to affect peoples' lives in many different areas. Here are some examples:
* Users need support in finding information and entertainment from the electronic marketplace. The dynamically changing data streams available to the user should be sorted and filtered into a manageable amount of high-value content in a customised fashion. In this thesis, this application area is of primary interest.
* In increasingly mobile and heterogeneous environments, messages must be filtered and routed intelligently to the recipients, also taking into account the capacity of the receiving device. This is also an interesting dimension in creating personalised services.
* Knowledge workers need support in the decision-making tasks. Agent technology can provide tools for more comprehensive decision-making process by efficiently sharing the information between the people involved and by assisting in the analysis of this information.
* There is a need to automate tasks performed by administrative and clerical personnel to reduce labour costs and increase office productivity. Intelligent agents can be used to improve such work processes, by automatically managing electronic information and giving tools to better co-ordinate these activities.
* People constantly need to learn new skills. Intelligent agents can be used as software advisors that are specialists in some limited knowledge domain, and that can teach the user to do new tasks. Agents are well suitable for these kinds of applications for their ability to model the user and to communicate with him or her. They can also monitor and register changes in their environment, and to learn from these changes.
The research in the field of intelligent agents is directed towards the ideal of agents that have human-like communication skills and can accept high-level goals and reliably translate these to low-level tasks.
Although the term agent is widely used, it has no single universally accepted definition. However, an agent can be considered as a system that has the following properties [Wooldridge, 1995]:
* autonomy: agents can operate without the direct intervention of humans or others, and they have control over their actions and internal state
* social ability: agents interact with other (possibly human) agents via some kind of agent-communication language
* reactivity: agents perceive their environment, and respond in a timely fashion to changes that occur in it
* pro-activeness: agents do not simply act in response to their environment, they are able to exhibit goal-directed behaviour by taking the initiative
The above definition is so called "weak notion" of agency. A stronger notion of agency, used particularly in artificial intelligence, defines an agent to be a computer system that has the properties identified above and such additional human-like properties as knowledge, belief, intention, obligation and emotion [Shoham, 1993].
The idea of employing agents to delegate computer-based tasks has been first introduced by visionaries such as John McCarthy, Nicholas Negroponte and Alan Kay:
"Computer consoles are installed in every home... everybody will have access to the Library of Congress... the system will shut the windows when it rains." [McCarthy , 1966]
"Omnipresent machines, through cable television (potentially a two-way device), or through picture phones, could act as twenty-four-hour social workers that would be available to ask when asked, receive when given." [Negroponte, 1970, p.55]
"In ten years, we will be hooked up to more than a trillion objects of useful knowledge, and no direct manipulation interface can handle that. People are not going to sit down with super SQL applications and start fishing around the entire world for things that might be of use to them. Instead, the interfaces are going to be 24-hour retrievers that are constantly firing away doing things". [Kay, 1990, p.241]
Also several computer manufacturers have adopted the idea of agents to illustrate their vision of the interface of the future. Apple Computer introduced the Knowledge Navigator, a video presentation of human-computer interaction in the year 2010.
The scene is set in a university professor's office, and the story portrays the professor using his computer to carry out variety of tasks, including answering electronic mail messages, replying to phone messages and interacting with his colleague to create a joint presentation. Communication with the computer uses voice recognition to interpret spoken commands. All the tasks executed by the computer are performed using a human-like agent able to express emotions. The agent screens incoming telephone calls, looks up telephone numbers in a directory, dials calls and generally manages the interaction between computer and the user.
Like artificial intelligence before it, the loose specification of the meaning of "agent" has made the concept available for misuse. There has been an explosion recently in the interest in intelligent agents, and it has become one of the buzzwords of the software industry. There is a large number of "agent"-products available that do not meet the above criteria of an agent. The idea of delegating tasks to a computer has also created unrealistic expectations of what agents can do.
A product called `At Your Service', from Bright Star, whose promotional literature starts with, `Remember the excitement you felt the first time you turned on a Mac? Now you can relive the magic and realise its full potential with At Your Service, the first animated Desk Accessory to give your Mac a 'human' personality. At Your Service features Phil, your Personal Assistant...he talks...he listens...he works for you!' In fact, this program is pretty trivial: it utters a spoken greeting when the Mac is turned on, issues reminders for preset events, issues alerts when email arrives, reminds you to stop typing every few minutes to ease hand and eye strain, contains a screen saver, and so forth [Foner, 1995].
Any agent should have a measure of autonomy from its user. A more autonomous agent can pursue agenda independently of its user. This requires aspects of periodic action, spontaneous execution, and initiative, in that the agent must be able to take pre-emptive or independent actions that will eventually benefit the user. Intelligent agents typically perform three functions [Foner, 1995, Hayes-Roth, 1995]:
* perception of dynamic conditions in the environment
* action to affect conditions in the environment
* reasoning to interpret perceptions, solve problems, draw inferences, and determine actions
Two types of agents can be used to provide agent-based multimedia services: interface agents and information agents. I have categorised these agents further in doers and watchers. Figure 7 illustrates this idea.
Interface agent is a computer program that employs artificial intelligence techniques to provide assistance to a user dealing with a particular application. The metaphor is that of a personal assistant who is collaborating with the user in the same work environment. [Maes, 1994a, p.31]
Information agent is an agent that has access to at least one, and potentially many information sources, and is able to collate and manipulate information obtained from these sources to answer queries posed by users and other information agents. [Papazoglou et al., 1992]
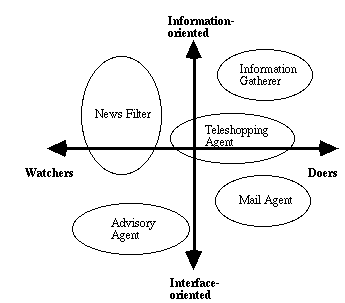
Doers are agents that are tightly integrated into the underlying application and network infrastructure. They can utilise many of the particular activities supported by the environment. They are able to communicate with other agents and perform different kinds of actions on user's behalf. For instance, a mail agent can learn to automatically organise and forward incoming messages, or to request information from other systems. Another example of a doer is a softbot (software robot):
A softbot is an agent that interacts with a software environment by issuing commands and interpreting the environment's feedback. A softbot's effectors are commands (e.g., UNIX shell commands such as mv and compress) meant to change the external environment's state. A softbot's sensors are commands (e.g., pwd or ls in UNIX) meant to provide information [Etzioni, 1994, p. 10].
Watchers are agents that continually look for information or some other event that meet predefined criteria. These agents can be trained to watch a continual information stream and find relevant objects using content-based or other information filtering techniques. Watchers are able to adapt their behaviour according to the changes in the environment.
Advisory agents are examples of watchers. They offer instruction and advice to help the user to do his work. They are experts in particular domain and are able to learn such things about the user as level of expertise, programming style, and personal interests.
The currently dominant interaction metaphor of direct manipulation requires the user to initiate all tasks explicitly and to monitor all events. This metaphor needs to change if more and more untrained users are to make effective use of computers and networks. Autonomous agents can be used to implement a complementary style of interaction, referred to as indirect manipulation. The user is engaged in a co-operative process in which human and computer agents both initiate communication, monitor events and perform tasks. The metaphor for intelligent agent is a personal digital assistant (PDA) that learns the user's interests, habits and preferences.
The following futuristic scenario about the capabilities of a PDA is adapted from [Shoham, 1993]:
You are editing a file, when your personal digital assistant requests attention using a mobile connection link between your PC and the network. You have received an email message, that contains notification about a paper sent to an important conference, and the PDA has correctly predicted that you would want to see it as soon as possible. The paper has been accepted, and the PDA has started to look for travel arrangements, by consulting a number of travel service providers.
A short time later, your list of incoming messages will include a summary of the most suitable travel options, with links to video presentations about moderately priced hotels that have rooms available during the conference days. You confirm the flight arrangements, and neglect the hotel presentations. Instead you ask the PDA to reserve a room from the hotel that has the highest price/quality rating. Michelin Global Hotel Guide provides this information for your PDA for a small service fee. The PDA asks you, if the cost of the flights and the hotel room should be discounted from your electronic account. You ask for an invoice instead. Your PDA will contact Michelin Global Hotel Guide without prompting when making hotel reservations next time.
The user and the agent are collaborating in constructing a "social contract". The user specifies what actions should be performed, and the agent specifies what it can do and provides results. This is best viewed as a two-way conversation, in which each party may ask questions of the other to verify that both sides are in agreement about what is going on [Foner, 1995].
* Competence. How does an agent acquire the required knowledge to assist the user?
* Trust. How can we guarantee that the user feels comfortable delegating tasks to an agent?
The machine learning approach for interface agents used at the MIT Media Laboratory's Autonomous Agents Group relies on the idea that the agent is given a minimal amount of background knowledge, and it learns appropriate behaviour from the user and other agents. The agents become more competent, as they accumulate knowledge about how the user handles certain situations.
When delegating tasks to agents, there is always a certain risk that the agent will do something wrong. The decision to trust the agent must be based on both our internal mental model of what the agent will do (how much we trust it) and the domain of interest (how much a mistake will cost us). Agents are most useful in domains in which graceful degradation and the correct balance of risk to trust can be obtained [Foner, 1995]. Learning approach makes the agents also easier to be trusted, since the user is able to incrementally build up a model of the agent's competencies and limitations.
The agent does not have to be an interface or layer between the user and the application. Most successful interface agents implemented so far have been those that do not prohibit the user from taking actions and fulfilling tasks personally bypassing the agent.
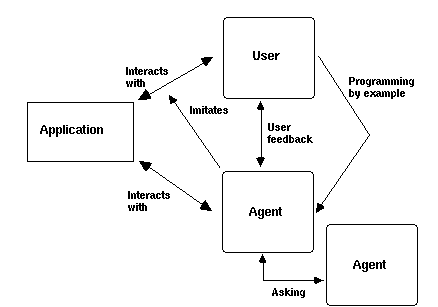
Figure 8 illustrates how the interface agent can learn in four different ways [Maes, 1994a, p.34]:
* Imitation. The agent observes and imitates the user's behaviour by "looking over the shoulder", and can offer to automate regular behaviour patterns found.
* User feedback. The agent can adapt its behaviour based on indirect or direct feedback. Indirect feedback happens when the user neglects the suggestion of the agent and takes a different action instead. The user can also give explicit feedback[6].
* Learning by example. The agent can learn from the examples given explicitly by the user.
* Other agents. The agent can ask other agents for advice, and learn from experience which agents are worth trusting.
Agent-oriented systems are widely seen as examples of anthropomorphic[7] user interfaces. However, interface agency does not necessarily imply a need for anthropomorphism. The role of the interface agent could also be more ubiquitous: the agents should stay out of the way and mostly out of sight. They could be ready to answer queries about their state and actions, but otherwise remain totally invisible to the user. Mark Wieser from Xerox PARC argues:
The computer today is isolated from the overall situation, and fails to get out of the way of the work. In other words, rather than being a tool through which we work, and thus disappearing from our awareness, the computer too often remains the focus of attention. And this is true throughout the domain of personal computers, palmtops, and dynabooks. The characterisation of the future computer as the "intimate computer", or "rather like a human assistant" makes this attention to the machine itself particularly apparent.
The problem is not one of "interface". It is not a multimedia problem, resulting from any particular deficiency in the ability to display certain kinds of real-time data or integrate them into applications. The challenge is to create a new kind of relationship of people to computers, one in which the computer would have to take the lead in becoming vastly better at getting out of the way, allowing people to just go about their lives [Wieser, 1993].
The increasing diversity and volume of accessible online data makes the existing tools for searching and browsing information less effective. The increasing use of multimedia data, especially audio and video, has amplified this trend. As an example of an information agent architecture, I introduce here a system for distributed resource discovery called Harvest[8].
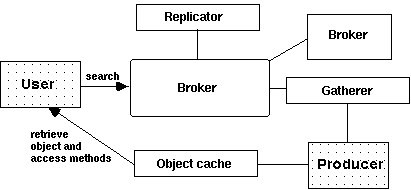
Figure 9. The Harvest architecture [Bowman et al., 1994, p.766]
The most important agent-based modules of Harvest architecture are the information gatherer and the information broker. These are explained further in the following sections of this chapter. Replicator is a subsystem that mirrors the contents of brokers between sites. The architecture includes also a hierarchical object caching subsystem. The important agent part missing from the architecture is the user navigator that can access the information resources.
Gatherers collects indexing information from information sources. Current research areas concerning information gathering systems include:
* Indexing. What indexing methods are appropriate and feasible for knowledge navigation systems? How can indices be extracted from data?
* Metadata. What knowledge about information and their sources should be represented? How to represent metadata?
* Reasoning. How query algorithms and languages could be enhanced? How to increase the information content for the user, for example by means of abstraction and summarisation?
* Planning and learning. How to generate plans for accessing information sources? How to interleave planning and execution? How to deal with incomplete information? How to learn about the contents of information sources?
Widely used information gathering agents today are programmable World-Wide Web wanderers and index makers (worms, spiders, robots, WebCrawlers)[9]. Perhaps the most successful of the WWW spiders is Lycos[10], developed at the Carnegie Mellon University [Mauldin, 1995].
Lycos completes currently over 500,000 connects per day, and it has become the most widely used Internet search index and engine. Lycos continually builds a model of entire WWW. As Lycos locates new documents, it builds an abstract that consists of metadata such as title, headings, 100 most "weighty" words, first 20 lines, size in bytes, and number of words. The catalog is continually updated by the Lycos robot that searches the Web, builds the abstracts, once a week merges databases into a single catalog, and catalogues the abstracts collected.
The Web is a forest of trees, in that each server is a root of a tree of files. Lycos explores the Web in a random search fashion using heuristics that give preferences to certain types of pages (server home pages, short URLs[11], etc.). Lycos uses its own retrieval engine called Pursuit that provides relevance-ranked retrieval of abstracts from the catalog.
Lycos can be used to measure the size of the Web. In April 1995, the estimate of the Web size was 4,051,340 URLs, 23,550 servers, and 29,9 gigabytes of text.
An information broker can provide a query interface to gathered information. Brokers retrieve information from one or more information gatherers or other brokers, and incrementally update their knowledge about data sources. In a multiagent environment, the broker has an active role. It communicates with users and other brokers using some agent communication language.
The brokers can be considered as knowledge-based mediators that employ retrieval strategies to gather information relevant to a user's request. Mediator is a module that occupy an explicit active layer between the user applications and the data resources. The role of a mediator is to simplify, abstract, reduce, merge, and explain data [Wiederhold, 1992, p.42].
Open issues in information brokering include:
* Brokering services. What are the most promising applications for information brokers?
* Knowledge sharing. What languages and protocols should be used for communicating knowledge between brokers? How to acquire information from users or other systems?
* Mobility. What is the role of mobile information brokers?
* Scalability. How does the brokering approach scale up to large user communities and large data objects?
Knowledge navigation agents are knowledge-based interfaces to information resources. They allow users to investigate the contents of complex and diverse sources of data in a natural manner. Examples of such systems include, information agents that users can direct to perform information finding tasks, intelligent browsers that can help direct user through a large multi-dimensional information space
The Internet is a good example of a potentially rich source of useful information. Traditionally finding information from the Internet has been a privilege reserved for relatively experienced users with a working knowledge of UNIX and a general idea of where the information was. The recent Internet tools, such as Wide Area Information Systems (WAIS) and WWW provide better access to Internet information. Although important, browsing is limited, and often very time-consuming form of getting useful information. Current Internet browsers show the users the way through the maze of information, but they do not actually do the navigation for them [Roesler & Hawkins, 1994, p.25].
Open research issues in knowledge navigation include:
* Retrieval and filtering. How can a knowledge navigation system adapt to a changing knowledge environment and to user needs?
* User modeling and learning. How to model and learn user preferences? How to "unlearn" by using non-monothonic reasoning?
* User interfaces. What are the characteristics of a useful navigational interface? What role can agent metaphor play in such interfaces? How to visualise large information spaces? How can a navigation system orient the user in the information space?
* Multi-source integration. How can multiple data and knowledge sources be integrated to address users' needs?
* Multimedia. What are the challenges presented by multimedia information sources?
As more and more people are connected into wide area networks, a common language that enables sophisticated collaboration and interoperability across the computers in these networks is needed. A mobile agent should be a piece of software that can run on any machine on a network, routing or filtering messages sent to a user and seeking out information or services on the user's behalf. This agent resides in the network using processing power of some network host that accepts its requests.
Transmission of executable programs between clients and servers is the basis for mobile agent-based computing. It extends the methods of remote dispatch of script programs and remote submission of batch jobs. Security concerns are very important, since any untrusted party can send code to be run on another computer. Mobile agents also enable spontaneous electronic commerce.[12]
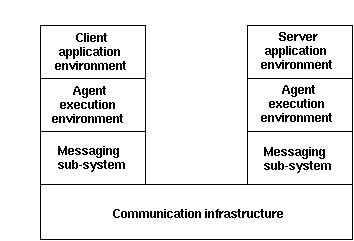
Figure 10. Conceptual model for mobile agent computing [Harrison, 1995]
The mobile agent concept is illustrated in figure 10. A client computer consists of an application environment, which contains one or more applications for interaction with a remote server. The applications are bound to an execution environment for mobile agents. They can pass parameters via the application programming interfaces (APIs) to various classes of agent programs, and the agent programs can return parameters to the application programs. When an application needs to perform a transaction, it will assemble the required information and then pass them via the API into the agent execution environment. This may correspond to an operating system process or thread. The agent execution environment may have access to many different agent programs, which provide different services to the client applications.
The program may be executed in either machine language or an interpreted (virtual machine) language. It is often preferable to express the agent in an interpreted language to support heterogeneity. Interpreted languages have the advantage of late binding, which enables the agent to contain references to functions or classes not present on the system at which it is launched, but which are available at the destination. Interpreted languages are also easier to make secure than machine language, since the language developer explicitly controls what system resources are available.
When considering client-server interactions, the alternatives for mobile agents are messaging, datagrams, conversations and remote procedure calls (RPCs). These can be divided in asynchronous protocols (such as messaging), and synchronous protocols (RPC).
Mobile agents employ messaging frameworks for transport. The distinctive characteristics of mobile agents are that they communicate both data and their own procedures and they exploit procedures resident at the client or server.
Mobile agents are also in many ways similar to RPCs. In current implementations, RPC communication is relatively fragile since they have been developed for Local Area Network (LAN) systems. Agent-based messaging provides reliable transport between client and server, without requiring reliable communication. The future Wide Area Network (WAN) protocols, such as Asynchronous Transfer Mode (ATM), should be able to provide robust methods for synchronous communication.
Agents provide good support for mobile wireless clients. Mobile computers and personal communicators are not continuously connected to the network. Currently they access the network mostly via circuit-switched lines, but in the future wireless access to packet-switched networks will be much more common [Harrison, 1995]. Mobile clients are able to develop an agent request - possibly when disconnected - launch the agent during a brief connection session, and then immediately disconnect. The agent sends the response message to the user when it has something to report. With mobile connections, the transmission of bandwidth hungry data objects can be automatically postponed until the user has a fast connection to the network.
The notion of mobile agents introduces also a number of open issues:
* Negotiation and agent-interaction protocols. How do agents query their environment and co-operate with each other?
* Authentication, digital signatures, and privacy. How to verify the source of an agent, and limiting facilities to allowed or trusted sources? How to protect private information?
* Resource control, accounting, and monitoring. How to limit the use of resources by an agent, or to account and charge for the resources consumed?
* Access control and safety. How to minimise the possible damage an agent can do?
Personalised multimedia services are mostly based on information filters that are acting as mediators between information sources and their users. These filters, or agents, should possess the knowledge and the functionality to examine the information in the sources and to select relevant information to individual users. Information filters can work on behalf of users finding relevant information overcoming "the information flood", as well as on behalf of sources targeting information to potentially interested users.
The possibilities for personalisation are not limited to personalised content. Other dimensions for personalisation, such as user's attitude towards the service, service time scale and different parameters regarding the actual delivery of information, can also be identified.
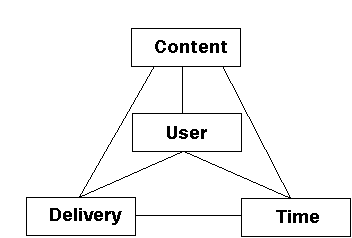
Figure 11. Four dimensions of personalisation
Figure 11 presents the main dimensions of personalisation in multimedia services. The content dimension is considered to include also information quality, and information presentation. The possibilities for personalisation are not so well understood today. This analysis is based on an article by Shoshana Loeb [Loeb, 1992], and the ideas presented in that article are further explored.
User types
Users have different information needs, and different methods of addressing the information. When a proactive[13] user can have a clear interest profile, for example all scientific publications in his domain of expertise, a casual user is typically interested in entertainment and daily news services. One of the main difficulties in creating a personalised service is that casual user's interests are difficult to specify and they are constantly changing [Stadnyk & Kass, 1992, p.49]. Casual users are not willing to spend hours teaching the agent their current preferences.
An information content provider can provide casual users with a selection of user profile prototypes tailored for that specific service provider. An individual user can then choose this initial profile, which will evolve later.
The need for explicit feedback in using the services and teaching the agent should be minimised in the case of casual users. The agent should be able to detect implicit feedback, and learn to adapt its behaviour according to this feedback.
Privacy protection
Personalisation depends on personal information, such as the rules about how people filter, select, and prioritise information. The users of personalised services are not willing to allow everyone to examine their preferences and usage patterns. On the other hand, people are willing to give away some personal information if the expected gains outweigh the possible threats for privacy.
Most sensible information from the user's point of view that should be protected are
* user profiles and queries
* usage history
* actual information delivered.
These privacy protection needs must be taken into consideration in personalised multimedia architecture design. In principle, introduction of different encryption methods in all transactions over the network insures the necessary level of privacy.
Encryption methods should also insure that service providers are not able to abuse the information collected about the users. Whenever possible, the consumer should be able to use personalised services in an anonymous fashion. For example, a consumer should be able to buy "a ticket" to view any movie the service producer has to offer, without revealing his identity.
User can ask for a specific level of required privacy, either when requesting a service or when a service is being offered to the user. If the privacy criteria are not met, all further transactions should be cancelled.
Willingness to pay
The service producers assume to have paying customers in the information supermarket. The Internet culture has promoted free flow of information - "information wants to be free". There are undoubtedly many Internet users who are not delighted to see the rapid commercialisation of the Internet.
Some users might continue to be interested only in free information sources, or in those that cost very little. Other users would be willing to pay for the service they get. Both of these user types can be satisfied by providing personalised service.
There are many different pricing models regarding multimedia services. The charging can be based on amount of transferred data, number of transactions made, connection time to the service, a fixed rate for a given usage period, or a combination of any of these models. The service can also be totally financed by advertisements.
A user can use economic filtering to set limits for the charge to be paid for the services and request a specific pricing method. The consumer agent and the producer agent could negotiate for a mutually acceptable method and level of charging.
Information lifetime
The value of information to the user is tightly related to the lifetime of different types of information. The potential lifetime can be indicated by the service producer and it can be
* minutes (stock market)
* days (news events)
* months (commercials)
* decades (scientific reports)
* centuries (classical music).
This fact should be taken into account when presenting the information to the user. The information with a short lifetime could take precedence over information with a long lifetime. Also some information items delivered could require an immediate answer from the user. New information could be more expensive than old information.
Source availability
The information producer should provide descriptors of the type and arrival frequency of the information. Some information items are stored and retrieved, others are "live" information sources to which the user "hooks on". Also live information sources should provide knowledge of their contents before transmission to be used in filtering. These "live" transmissions can also be stored at the production site for later retrieval.
Agent communication patterns
The filtering agent can deliver the information continuously as the information becomes available, synchronously, or asynchronously following user's requests. Synchronous service requires near real-time filtering and delivery. Asynchronous service depends on the availability of store-and-forward capabilities either at agent-to-consumer buffer or at some other storage facility at the user end.
Consumption patterns
The duration and frequency of user sessions may vary. In providing dedicated services to the user the usage may be continuous (email), regular (evening news), irregular (music). Also single session usage should be allowed. Agents should be able to schedule and orchestrate the multimedia presentations, taking these usage patterns into account.
Information media characteristics
The most demanding multimedia information forms are continuous media, audio and video. The form of information media affects the required performance of the filtering agent. The number of selections needed depends on the media type: much more news item selections are needed than full-length movies.
Also the high bandwidth requirements for continuous media transmission (1.5 - 6 Mb/s for entertainment quality MPEG compressed video) means that storing the entire contents in a buffer at consumer premises is not practical. In this case only a pointer to the video source should be stored in this buffer. Once the selection to receive the video transmission has been made, a continuous loop is formed between the user and the source.
Information transport characteristics
The communication architecture and available bandwidth determine to a large degree the location of the agent and the buffer sizes required. The service should be capable to adapt in different network infrastructure from broadband communications to wireless networks. The Quality of Service (QoS) parameters in network communications should include these transport characteristics.
User equipment
Jim Clark has suggested that the user equipment will be a TeleComputer, a low-cost computer designed as a multimedia player at home [Clark, 1992]. The intelligence and storage capabilities of this user equipment have a strong influence on the information-filtering scenarios that can be designed. Currently the multimedia technology is fuelling the convergence of computing, communication and consumer entertainment.
Information content attributes
The agents must examine the information items, or some attached metadata about them. Since the data items being filtered are not necessary text-based, efficient methods, such as full-text indexing, cannot always be employed. Although new pattern recognition techniques for image, sound and speech, have been introduced, their computing-intensive nature has so far prohibited wide acceptance of these methods.
Information quality
Information filtering system should be able to select items of good quality to the user. Currently we rely on reviews and recommendations made by domain experts. We should allow a mechanism where the quality can be expressed by accumulating the content ratings given to the information item.
The content rating can either be provided by a rating authority, an inspector who assures quality of a given information object, or by the user community collaboratively. The rating model can be hierarchical, where an inspector can authorise other inspectors to give quality reviews.
From:
Please express your interest in this article by circling the appropriate number on the reader inquiry card.
Low 710 Med. 711 High 712
To:
How did you like this article? Give a rating by pressing the button below. The current overall rating for this article is 3.52. Press here for detailed information and annotations.

Figure 12. The collaborative rating model
Another important way to ensure the quality to is to get recommendations from other persons, who have extensive domain knowledge or who share the same taste with the user.
Information presentation
In personalised services the user is given more control on the presentation of the information objects. The fundamental idea of Standard Generalised Markup Language (SGML) is that the presentation and the contents of information are separated from each other. One could argue that WWW is personalised already today, since each user can control some of the presentation attributes of text and images. The future implementation in WWW will include style sheets, so the content providers can hint how the information should be presented, but the user's preferences can override these hints.
We apply filters continuously in our everyday life. There are four main factors that reduce our incoming information stream:
* Inaccessibility. Most items and information are not in the information stream because they are either inaccessible or invisible to us.
* Pre-selection. Large amount of filtering is done for us. Newspaper editors select what articles their readers want to read, publishers select what book to publish, etc.
* Recommendations. We rely on friends and other people whose judgement we trust to make recommendations to us.
* Cost. We consider the information too expensive.
Information filtering is closely related to the task of information retrieval. The information filtering tasks are generally more complex and more difficult to automate than information retrieval tasks.
Information retrieval (IR) involves typically queries from relatively static databases to satisfy punctual information needs.
Information filtering (IF) refers to selection of data objects from a continuously changing dynamic stream of information. The goal is to select only those objects relevant to user's interests. Information filtering involves repeated interactions over multiple sessions with users having long-term goals.
Table 4. Differences between IR and IF
Characteristics Information Retrieval Information Filtering
(IR) (IF)
Usage patterns Single uses, one-time Repeated uses,
goals long-term goals, user
profiles
Type of data Structured, simple data Unstructured or
types semistructured data
Main concerns Collection and Distribution and
organisation of data selection of data
Time dependency Static databases Dynamic information
stream
Users Well-defined motivated Undefined user
user groups communities
Security issues Not important Very important
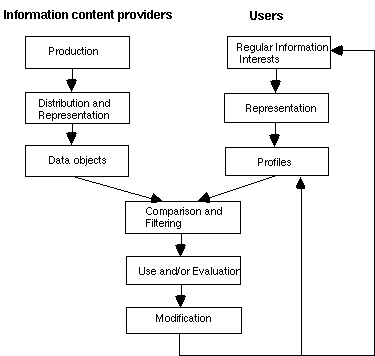
Figure 13. General information filtering model [Belkin & Croft, 1992, p.31]
Figure 13 shows the information filtering process in detail. The key issues are the content providers' representation of different attributes about the data objects, and the capability to model the information interests of the users.
Multimedia information filtering is carried out by an agent that selects the material relevant to the user from the electronic information marketplace. The information is selected using interest profile containing a description of user's preferences that have been explicitly given to the agent or the agent has learned by monitoring the user and other agents. The agent selects the material based on the user preferences, financial criteria, such as price, transaction cost, delivery cost, and other criteria, such as source credibility and quality ratings, age of a piece of information, etc.
Based on a survey of information sharing in organisations, three approaches for information filtering can be identified: content-based, social and economic [Malone et al., 1987a, p.391].
1. Content-based information filtering is based on the characteristics extracted from the available objects. These representations of the object contents are compared with a representation of the information needs of potential recipients and then using these representations to intelligently match the objects to receivers.
Keyword-based filtering and latent semantic indexing are examples of content-based filtering techniques. For example, the system may try to correlate the presence of keywords in an article with the user's taste. However, content-based filtering has limitations [Shardanand & Maes, 1995]:
* Either the items must be of some machine parsable form, or attributes must have been assigned to the items by hand. With current technology, multimedia items are very difficult to analyse automatically for relevant attribute information. Often this attribute information is not available.
* Content-based filtering techniques have no inherent method for generating serendipitous finds[14]. How can the system be able to recommend relevant material that the user could not possibly have known to ask in the first place? The system recommends more of what the user already has seen and liked before.
* Keyword-based searches have limitations and are more suitable for traditional information retrieval tasks. Scalability of the keyword-based approach is dependent on the use of fairly standard and correct vocabulary.
* Content-based filtering methods cannot filter items based on quality, style or point-of-view. For example, they cannot distinguish between a well written an a badly written article if the two articles happen to use the same terms.
Some content-based filtering techniques update the profiles automatically based on feedback about whether the user likes the documents that the current profile selects. This relevance feedback process can draw on Bayesian probability, genetic algorithms, or other machine learning techniques.
Chapter 4.3.1 introduces commercially available news filtering system, NewsHound. Newt is another example of a content-based filtering system that uses genetic algorithms for relevance feedback. It is further explained in chapter 4.3.2.
2. Social information filtering filters items based upon the recommendations of other people with similar tastes. It essentially automates the process of "word-of-mouth" recommendations. The recommendations may come from other trusted people whose opinions are highly valued, or from other agents. The agents performing social filtering do not attempt to correlate the user's interests with the contents of the items recommended. Instead, they rely solely on correlations between different users.
The basic procedure for social information filtering is as follows [Shardanand, 1994, p. 18]:
* A user profile is constructed over time, containing a record of the user's traits based on past history
* The user profile is compared with the profiles of other people collected by other agents, and each profile is weighted for their similarity with our user's profile. The metric used to measure similarity may vary.
* A group of the most similar profiles is taken, and used to construct an answer to some query for our user.
* This information is given to the user in an appropriate form.
The same can be done for the items themselves. Profiles for items, i.e. a record of how different users liked the item, can be constructed. The profiles of different items can be compared to find correlations. These correlations can then be used to answer user queries, as they enable us to find how different items relate to user's known tastes.
A social filtering system becomes more competent as the number of users in the system increases. It may need to reach a certain critical mass of collected data before it becomes useful.
Ringo and GroupLens are examples of social filtering systems. They are introduced in chapters 4.3.3 and 4.3.4.
3. Economic information filtering systems select data objects based on computations of cost-benefit to the user and through explicit or implicit pricing mechanisms. People have to make a cost-versus-value decision to determine whether to select a particular item.
The size of the object is one of the primary factors used by recipients to estimate its cost. Long text documents are more costly to read than short ones.
The production cost of information to its sender divided by the number of recipients can also give an estimate how valuable the information is. Optimal piece of information to the reader is often one that is customised to the reader's needs - at great expense to the sender [Malone, 1987a, p.392].
One possible approach, based on economic filtering, to reduce the number of "electronic junk" has been suggested by Peter Denning:
Filtering system is based on the observation that receivers use the cost of a message to its sender as a consideration in filtering. An electronic messaging system can use this approach by letting senders spend limited resources to signal receivers that a message deserves more than the usual priority. Some receivers might then have "asking prices" on their mailboxes that screen out all messages below a certain cost [Denning, 1982].
Other approach to economic information filtering is to give the user the possibility to control how much the filtering agent can spend on the information to be received. For example, the agent could have an upper limit that cannot be exceeded. When the agent runs out of money it returns the user the achieved results.
Most of the current experiments with intercommunicating agents assume that there is sufficient common interest among the agents to volunteer to help each other and to receive no direct reward for their labour. As the Internet becomes increasingly commercialised, one can envision a world where agents act on behalf of their users to make a profit. Agents will seek payment for services provided and may negotiate with each other to maximise their expected utility, which might be measured in electronic currency.
To my knowledge, there are no systems widely available where the techniques of economic information filtering have been used. Agoric Open Systems use optimisation technique based on economic model in which agents compete via marketing trading [Miller & Drexler, 1988]. These ideas of computational markets can be extended to information filtering. Market-oriented programming approach solves distributed resource allocation problems by formulating a computational economy and finding its competitive equilibrium [Mullen & Wellman, 1995]. In a project related to the University of Michigan Digital Library, a large-scale information services network is based on specialised information agents, that act as suppliers and producers in a computational information-services economy.
These problems are in the intersection of game theory, economics and distributed artificial intelligence. Also researchers at the System Analysis Laboratory of Helsinki University of Technology [Verkama, 1994] are studying reactive agent processes in organisations. They have built a prototype system called MART (Multi-Agent Reactions Testbed) to simulate interaction behaviour of utility maximising.
This chapter introduces some examples of current agent-related information filtering products and ongoing research projects. All of these systems produce the results of the filtering process as text, so the multimedia dimension is not taken into account in these example systems.
Verity's Topic search engine is embedded in many software products including Adobe Acrobat and Lotus Notes. Recently Verity has brought agents and topic query objects to the Internet. Topic Agents allow users and online providers to filter incoming information against interest profiles and send automatic alerts via personal WWW pages, electronic mail or fax. Topic objects also allow information to be automatically categorised and browsed by subject area.
Knight-Ridder's NewsHound[15] service uses Topic search engine to filter articles from a wide range of newspapers and wire services, as well as classified ads from the San Jose Mercury News. Selected articles and ads matching user's profile are sent to the user's electronic mailbox. The distributed material contains only textual items.
User's areas of interest are specified as query profiles, each composed of multiple search terms. There are three types of search terms: possible (may appear in the text), required (must appear in the text) and excluded (must not appear in the text). The full-text search is performed once an hour for each profile. NewsHound profiles are updated by using a form-based WWW interface in figure 14.
The NewsHound uses fuzzy logic to find the most relevant material. This means counting the number of possible and required terms found in an article and then assigning the article a selectivity score (1-100). The user can set the selectively level as a filtering criterion in each profile.

Figure 14. NewsHound profile form
The pricing is based on the number of query profiles the user has. The actual volume of information delivered to the customer is not relevant in pricing. From the service provider's point of view, the model of selling information agents that can be programmed by the users, is easy to manage.
NewsHound is based on keywords only, and there is no method of relevance feedback in the system. The main problem with the NewsHound approach is that it requires too much insight, understanding, and effort from the user. The user has to recognise the opportunity for employing an agent, create the agent, give explicitly the keywords required for the query, and maintain the agent's rules over time.
Newt (News Tailor) is a personalised news filtering system that helps the user filter Usenet Netnews. It is developed at the MIT Media Lab and implemented in C++ on a Unix platform. The user can create a set of agents that assist the user with the filtering of an online news source, and train him or her by means of examples of articles that should or should not be selected. An agent is initialised by giving it some positive and negative examples of articles to be retrieved.
Newt's system architecture was designed to meet the following goals [Sheth, 1994, p.8]:
* Specialisation. System must serve the specific needs of the user, and be able to identify patterns in user's behaviour.
* Adaptation. User's interest change over time, and the system must be able to notice this and adapt its behaviour accordingly.
* Exploration. Filtering system should be capable of exploring new information domains to find potentially interesting items to the user.
The agent performs a full-text analysis to retrieve the words in the text that may be relevant. It also remembers the structure information about the article, such as the author, source, and so forth. The user can also program the agent explicitly and fill out a set of templates of articles that should be selected.
When the agent makes recommendations, the user can give it positive or negative feedback for articles or portions of articles. This explicit relevance feedback increases or decreases the probability that the agent will recommend similar articles in the future [Maes, 1994b]. Test results show that relevance feedback as a technique is sufficient for profiles to specialise to static user interests. However, it cannot adapt as user's interests change.
Genetic algorithms used in Newt's learning module are an interesting approach for modeling adaptation and exploration in an information filtering system. An agent is modeled as a population of profiles that compete for the user's attention by presenting articles. Newsgroups are compared for similarity, and the similarity ratings are stored in a database. A mutation operator is used to create the next generation of user profiles that includes similar but yet unexplored newsgroups. This way new and potentially interesting information domains can be searched for the user.
The genetic algorithms used are quite computation-intensive, and the scalability of this approach has not been tested. The number of simultaneous users in experiments was less than twenty.
Ringo[16] is a social filtering system available in the World-Wide Web, which makes personalised recommendations for music albums and artists. Ringo's database of users and artists grows dynamically as more people use the system and enter more information. Ringo is also done at the MIT Media Lab.
People describe their listening pleasures to the system by rating some music. These ratings constitute the person's profile. This profile changes over time as the user rates more artists. Ringo uses these profiles to generate advice to individual users. Ringo compares user profiles to determine which users have similar taste. Once similar users have been identified, the system can predict how much the user may like an album or an artist that has not yet been rated by computing a weighted average of all the ratings given to that album by the other users that have similar taste.
The system determines which users have similar taste via standard formulas for computing statistical correlations. Three different algorithms have been tested [Shardanand & Maes, 1995]:
* Mean squared differences. The degree of dissimilarity between user profiles is measured by the mean squared difference between the two profiles. Predictions can then be made by considering all users with a dissimilarity to the user which is less than a certain threshold L and computing a weighted average of the ratings provided by these most similar users, where the weights are inverse proportional to the dissimilarity.
* Pearson r. Pearson r correlation coefficient is used to measure similarity between user profiles. This coefficient ranges from -1, indicating a negative correlation, via 0, indicating no correlation, to +1 indicating a positive correlation between two users. Again, predictions can be made by computing a weighted average of other user's ratings, where the Pearson r coefficients are used as the weights. This algorithm makes use of negative correlations as well as positive correlations to make predictions.
* Constrained Pearson r. A modified version of the Pearson r algorithm which takes the positivity and negativity of ratings into account, so that only when there is an instance where both people have rated an artist positively, or both negatively, will the correlation coefficient increase. This algorithm first computes the correlation coefficient between the user and all other users. Then all users whose coefficient is greater than a certain threshold L are identified. Finally a weighted average of the ratings of those similar users is computed, where the weight is proportional to the coefficient.
The constrained Pearson r algorithm performed best, when developers tested different algorithms for social filtering.
Ringo's competence to give accurate predictions has risen with the number of users. After a lot of negative feedback in the beginning of the experiment, Ringo has turned out to be a success. One of the most important reasons for Ringo's appeal has been that it is not a static system. The database and user base is continually growing and Ringo's recommendations to the user are changing. There are a large number of regular users that find the service useful.
The scalability of the service is questionable. Currently Ringo has a couple of thousand subscribers. The correlation calculations have to be done separately for each user, and that requires a lot of processing power. Advances in used algorithms, such as different clustering techniques, can be used to reduce the number of similarity measures that need to be computed.
The application domain of Ringo is well defined, and it is fairly easy for people to give their rating about music. The same approach can be somewhat more difficult to use, when the items to be rated can include any kind of data. This is the case in another social filtering application, Webhound[17]. Webhound filters interesting WWW documents to its user. There is not yet material available about the results of this experiment.
I was surprised by the accuracy of the predictions that Ringo gave me. Ringo proposed many albums that I already have, and some totally new artists that have indeed matched my taste after I have tried them out. In addition, Ringo is fun to use.
GroupLens is a system for collaborative filtering of Usenet Netnews. Although very successful medium for sharing information, the netnews has too many articles of no value to their readers - the signal to noise ratio is too low. GroupLens provides the user a possibility to rate articles and passes these ratings to other readers. Social filtering techniques are used to predict suitable articles for readers. GroupLens customises score predictions to each user, thus accommodating differing interests and tastes.
The GroupLens architecture is designed to meet the following criteria [Resnick et al., 1994]:
* Openness. Many different news clients and ratings servers should be able to participate in GroupLens.
* Ease of use. Ratings should be easy to form and communicate, and predictions easy to recognise and interpret.
* Compatibility. The architecture should be compatible with existing news mechanisms.
* Scalability. As the number of users grows, the quality of predictions should improve and the speed not deteriorate. One potential limit to growth is transport and storage of the ratings.
* Privacy. Some readers would prefer not to have others know what kinds of articles they read and like. In GroupLens there is a possibility to use a pseudonym.
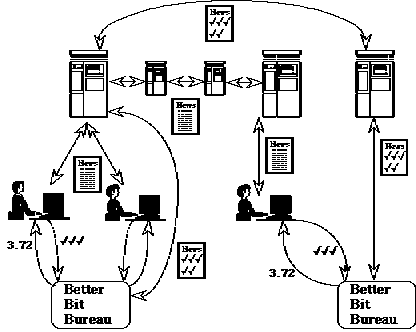
Figure 15. The Better Bit Bureau architecture
Better Bit Bureaus in figure 15 are servers that gather and disseminate the ratings. They also provide scores that predict how much the user will like the articles. The ratings are communicated by the way of news servers, and the same propagation scheme is used as in news articles. Clients connect to local news server, and can connect to Better Bit Bureau that uses the same or a different news server. Better Bit Bureaus employ Pearson r correlation coefficients to determine similarity between users.

News reader clients display predicted scores for news items and make it easy for users to rate articles after they have read them. Figure 16 shows the modified NewsWatcher client for Macintosh that displays predicted scores as bar graphs alongside article's author and header.
Currently, there is a limited testbed for GroupLens architecture. The system will be distributed for wider test use in the near future.
In this chapter, the role of agents in providing interactive multimedia services is defined and an overall architecture for personalised services is introduced. This chapter will also cover the most important modules of this overall architecture, and some architectural requirements of user modeling, metadata, dynamic multimedia presentations, and scalability are presented. Full definition of these requirements is not part of this work.
Personalised multimedia is an ideal and challenging task for autonomous agents. Users are looking for personal assistants that are constantly monitoring the network for interesting information and services. On the other hand, the service providers try to differentiate among thousands of other information production sites. How can the producers target their message to the right customers? [Alexander, 1995, p.3]
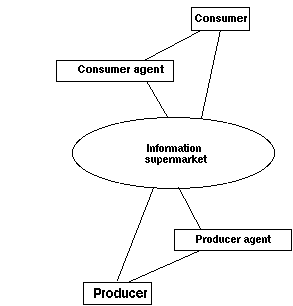
Figure 17. Agent-mediated information services
Multi-agent intercommunication methods enable message passing between agents in a heterogeneous network environment. The consumer agent transmits user requests for potential producer agents and filters messages according to user preferences. The producer agent can advertise the services to consumer agents in the network. Agents negotiate how, when, and which information items should be transmitted. Agents are also able to consult other agents for suggestions and further information. Finally the agents assist in completing necessary data transfer tasks and financial transactions.
An abstract information filtering architecture consists of four logical units:
* producer that acts as the information source
* agent that filters the information
* consumer that receives the information
* other agent that can act as a client or a server to the first agent
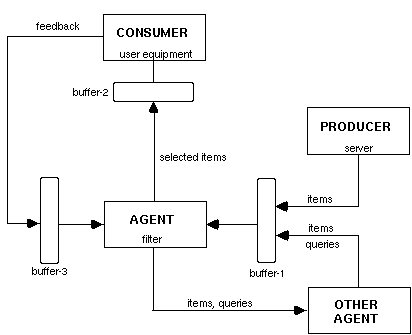
Figure 18. An information filtering architecture, adapted from [Loeb, 1992, p.40]
The producer (or producer's agent) presents some descriptors of the multimedia information items to the filtering agent. The agent forwards to the user a subset of items selected based on user profile. Users may have the option of providing the filter with feedback either explicitly (i.e. rating mechanism in the user interface) or implicitly (i.e. skipping over the uninteresting items).
The flow of information may need to be buffered. Buffering enables pre- and post-processing of filtered information as well as temporary storage for the filtered items. The role of the producer-to-agent buffer-1 is to enable limited "look-ahead" facility on pre-filtered information. The agent-to-consumer buffer-2 can act as a temporal storage before the information is displayed, and different kinds of postprocessing can be done for filtered data objects. The consumer-to-agent buffer-3 allows for flexibility in processing user feedback.
The agent-to-agent dimension in information filtering is presented by "Other agent" that can act as a source of information for another agent. The agents use some form of agent communication language to communicate with each other.
Agents may need to access only descriptors of the multimedia items, not their actual contents. Information source, producer or other agent, provides logical addresses for the selected items, and the agent presents these to the user. The selected items will then be fetched from the information producers and presented by the user's multimedia presentation control module. The cost of information to be delivered can also be presented to the user, before the actual delivery is done.
The user should not be burdened with the task of seeking out potentially interesting information sources. In information filtering tasks, this interaction is handled by automated mediator programs. In the mediator architecture [Wiederhold, 1992] a class of software modules mediates between workstation applications and the databases. This architecture has three layers, where the mediation is distinguished from the user-oriented processing and from database applications:
* User layer. Independent applications, that are managed by end-users.
* Mediator layer. Multiple knowledge modules, that are managed by domain specialists.
* Database layer. Multiple databases, that are managed by database system administrators.
In addition to the previous generalised filtering architecture, multiple specialised filters, and multiple producer databases are included in the mediator architecture (see figure 19).
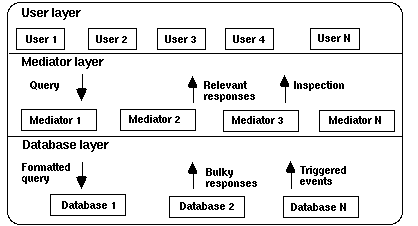
There is no single mediator, or agent, that handles all tasks for all applications, and the idea that agents always communicate directly to one another will not scale to a very large number of interacting agents. The mediators can be grouped into federations, or agencies, of agents. Metalevel mediators can be responsible of coordinating the communication between agencies and of providing different services:
* Finding agents. "What agents are connected?" or "Is agent x connected?"
* Yellow pages. Finding agents capable of performing a task. "What agents are capable of answering the query x ?"
* Direct communication. Sending a message to a specific agent.
* Translation. Translating messages between agent communication languages.
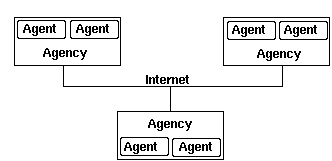
Figure 20. Federated agent system [Genesereth & Ketchpel, 1994, p.51]
There are also many other key problems to be solved in the agent-mediated multimedia architecture, such as applicable multimedia information models, real-time requirements, message synchronisation, payment for services, security, etc. Some of these issues are further explored in later sections of this chapter.
System architecture for personalised multimedia services is presented in figure 21. This architectural presentation is simplified by considering producers of services, brokering services, and other agents that recommend services as one single SuperServer entity that can answer customer's queries.
The results of multimedia production are stored as objects in a database, as well as metadata about these objects available. These two functions are provided by two different servers, because the producer agent needs to access only the metadata server to keep track of available items. The metadata database is very small in comparison with the actual multimedia object repository available at the storage server. The contents of the metadata database can be easily cached and replicated between server sites. Storage services can also be provided by specialised companies (for example network operators) who have the needed storage and bandwidth capacity.
The server includes the security and session control layers. User authentication and authorisation is carried out before the consumer agent is allowed access to database contents. In some services, the metadata server can be accessible to everybody, but the object repository is accessible only to authorised users.
The session control layer is responsible to record all the transactions for usage analysis and billing. It is also responsible of intelligent resource allocation (user distribution, caching, bandwidth, server load, etc.). These scalability problems are studied in detail in the OtaOnline project.
The consumer and producer agents can be implemented as agencies, where there are multiple filtering agents, each with their specific task. Here I have treated them as single agents. The agents are mobile, so the consumer agent can traverse to the host where the producer agent resides, and vice versa. This is not necessary in all inter-agent communications.
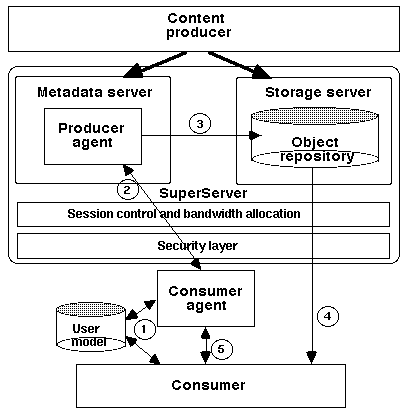
Figure 21. An architecture for personalised multimedia
To choose personal multimedia presentations, the customer agent monitors and analyses continuously customer's preferences and updates the user model. Different machine learning methods can be used in this process. The user can always examine and change the contents of the user model. The user can also teach the consumer agent by giving explicit feedback.
An example of data flow in this system architecture is presented by numbered arrows in figure 21:
1. User modeling. Customer's preferences are maintained in a user model.
2. Content queries and promotion. Customer agent sends a query to the producer agent to receive items that match the user interests. Also parts of the customer's user model can be sent to be used in social information filtering performed by the content producer. Producer advertises its services to consumer agents.
3. Dynamic presentation. The matching objects are ordered from the object repository. A scheme for multimedia presentation is created dynamically at the server. The retrieval times for different continuous media presentation are scheduled. This also has an effect on the caching made by the SuperServer. Cache usage can be optimised, when the presentation times are known in advance.
4. Delivery. The user receives multimedia data objects from the storage server according to the scheduled presentation. The user can cancel the delivery, and has also the possibility to re-schedule the presentation.
5. User feedback. The user gives feedback to the consumer agent by rating the delivered presentations. The agent can also detect implicit feedback.
The high-level goals of the consumer agent in personalised multimedia services are
* to minimise the amount of undesirable information
* to model the user's requirements
* to present the information to the user in a convenient form
* to minimise cost
A consumer agent consists of several sub-modules presented in figure 22. This modular design is partly based on the work done at the Personal News Assistant project[18].
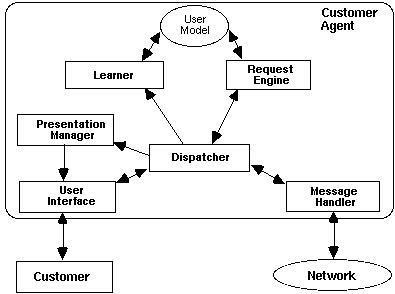
Figure 22. Modular structure of a consumer agent
Request Engine
Request engine formulates queries to information sources based on user's information needs. It interprets the query results when they are available. The request engine can also answer queries made by other similar agents. This dual client and server role may be better satisfied by two different modules.
Message Handler
Any messages in agent intercommunication are handled by the Message Handler. It composes messages to be sent, and decomposes messages sent by other agents and passes the information to other modules.
Learner
Learner is responsible for maintaining the user profile. Learner receives all the user feedback. It should be able to modify the user model based on the analysis of the feedback to better match user's interests.
User Interface
There should also be standard features in the user interface, such as mechanism to give explicit feedback and tools to examine and change the contents of the user model.
Presentation Manager
The multimedia presentations of the personalised service can be formatted dynamically at the user end by the customer agent as the information becomes available.
Dispatcher
Dispatcher is the core of the agent that delegates the unfinished jobs to other modules.
The goals of the producer agent are
* to be aware of the contents of the object repository
* to find maximum number of consumer agents for the services
* to optimise the presented information for available bandwidth and user equipment
* to co-operate with other server modules in the production of metadata
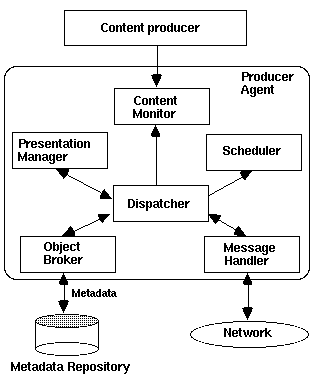
Content Monitor
Content Monitor keeps track of the updates in the contents of the object repository.
Object Broker
Object Broker accesses the Object Repository, or a separate Metadata Repository, if it exists, for information about the multimedia objects. It allocates the potential customers in the network by sending advertising messages to the "Yellow Pages" servers. It can also contact the consumer agents directly to promote some new service of information.
Message Handler
Any messages in agent intercommunication are handled by the Message Handler. It composes messages to be sent, and decomposes messages sent by other agents and passes the information to other modules.
Scheduler
Scheduler is responsible for synchronisation and orchestration of time-dependent multimedia presentations.
Presentation Manager
The presentations of the personalised service are usually created dynamically at the server based on the metadata about multimedia objects and the timetable provided by the Scheduler.
Dispatcher
Dispatcher is the core of the agent that delegates the unfinished jobs to other modules.
There should be components of user modeling and learning in the agent architecture. User modeling process is complicated, since the knowledge about the user can be incomplete, not available, and contradictive. The modeling can be done in a satisfactory way using non-monotonic reasoning techniques. These are very broad topics and subject to intensive research in the field of AI. This section is a brief introduction to these problems.
The user model is the source of knowledge containing the user's needs and preferences in certain domains. The model is used to decide whether some information is relevant to the user's preferences and to infer the user's goals and plans. The user model consists of observations of user's behaviour, deductive beliefs (inferred data), and of stereotypical beliefs derived from user stereotypes. The stereotypical knowledge can be definite (necessarily true) or default descriptions about the user of a certain type.
In multimedia services these dynamically changing needs can be long-term or short-term. Very short-term needs are difficult or impossible to learn [Sormunen, 1994]. The system must also be able to "unlearn" the knowledge as user's needs change over time. This is the task of a belief revision system. The model control system is needed to allow user access to review and change the contents of the user model in a convenient way. Figure 24 illustrates the structure of the user modeling system. This structure is based on models in [de Kleer et al., 1989, p.228] and [Huang et al., 1991, p.90].
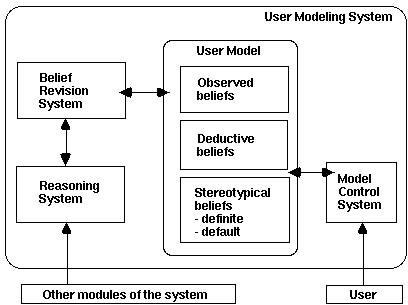
Doppelgänger is a user modeling system developed at the MIT Media Lab. It introduces the idea of community beliefs. They are changing continuously as their constituents change, they can be generated automatically, and membership in a community is matter of degree rather than "yes" or "no" [Orwant, 1993, p.22]. This also means that the personalisation can be done at the community level. For example, there could be a special edition of a personal newspaper to all students of software technology at the Helsinki University of Technology. Social filtering can be used to determine, which communities the user should be part of.
The sensitive nature of the user model implies that there should be a security mechanism controlled by the user to allow and disallow access to this information. The contents of the user model should be encrypted. The dissemination of non-sensitive information in the user profile can be implemented by organising the model in three security levels of information:
* Private. These information items are accessible to the user only, they can not be given to outside agents. When private information is used in finding services in the network, the identity of the user should not be revealed.
* Trusted. The user can specify trusted agents to whom these items can be accessible. Trusted agents can be grouped and the authorisation may done on a group level.
* Public. This part of the user model is accessible to anyone who is allowed access to user's environment.
Traditional database management systems (DBMSs) deal primarily with numeric and character data. Multimedia database systems should be capable in managing structured text, images, graphics, audio, and video. The features required for full-fledged multimedia database systems include:
* Support for large data values.
* Stream-oriented query languages
* Long real-time operations.
* Support for dynamic linking
* Metadata about the logical structure of the data objects
The database system should use a metadata approach for information management and presentation. Metadata includes information about the location and characteristics of the data to be retrieved. Metadata must also be available about the logical structure of the data objects and relationships between them. This information is used to create dynamic hyperlinks between the data objects. For example a newspaper article may be accompanied with a video presentation about the news topic.
Metadata approach enables decoupling of the data delivery process (for example raw video transmission) from the database management functions [Little & Venkatesh, 1994]. There can be dedicated metadata servers, that enable interactive browsing of the multimedia titles and descriptions of their contents. The producer agents should have access to these metadata servers. The metadata enables them to provide descriptors about their data objects to other agents. These metadata servers can be coupled with the SuperServer's resource management mechanism to better manage system resources. When resource updates occur (resource removal, relocation, new resource generation) only the entries in the metadata server's database need updating for the change to be visible to the entire user community.
An Internet Engineering Task Force (IETF) has been formed to specify a Uniform Resource Characteristic (URC) method for encoding information about a given network resource [Mealling, 1995]. URC encoding is based on the use of attribute / value pairs in the following format:
[attribute_name] : [value]
where attribute_name is of a specified set of pre-defined attributes that should be recognised, but not necessarily acted on, by all implementations.
The URC attributes and values are accessible as header information about the objects in the WWW without the retrieval of the actual data objects. The following example illustrates the use of URC concept:
URN: HUT:OtaOnline:Iltalehti Title: Iltalehti Home Page Date of Creation: 19.5.1995 Version: 1.0 Author: Mauri Mattsson URL: http://otaonline.hut.fi/otaonline/iltalehti/ilhp.html Content-Type: text/html Size: 120K Cost: FIM 2.50Uniform Resource Name (URN) is a mechanism to be implemented for identifying unique names for objects on the Internet regardless their physical location.
The production process of personalised multimedia necessarily includes the transformation of the selected multimedia objects to a wrapped presentation. This dynamically created presentation is then transmitted to the customer. The most important technical considerations are real-time requirements and network requirements.
Customers have different communications requirements for different applications. Temporal media are less sensitive to errors and loss during transmission than text or numeric data. However, transmission quality degrades as errors increase, so a maximum acceptable error rate is required. The Quality of Service parameters for transmission can be negotiated between agents.
Dynamic linking
The metadata available can be used in dynamic linking of data objects. A sophisticated system for presentation management and scheduling is needed to create presentations on-the-fly.
The multimedia presentation can be stored in the database in some platform independent format. The dynamic linking process can include also the function of translating or compiling the contents of the objects to the format required by the end-user equipment.
Network infrastucture
The transfer of audio and video data in multimedia services requires networks specifically designed for multimedia traffic. Traditional LAN environments and multimedia communications have different characteristics as summarised in table 5.
Table 5. Traditional communications vs. multimedia communications. [Fuhrt, 1994, p.52]
Characteristics Traditional data Multimedia transfer
transfer
Data rate Low High
Traffic pattern Bursty Stream-oriented highly
bursty
Reliability requirements No loss accepted Some loss accepted
Latency requirements None Low (for example 20 ms)
Mode of communication Point-to-point Multipoint
Temporal relationship None Synchronised
transmission
One stream of MPEG-2 compressed digital video requires a bandwidth of 4-10 Mbps, which is enough to saturate a local area network such as an Ethernet. Multimedia network backbone should be capable in supporting several thousands simultaneous video streams, so bandwidths of Gbs are needed. Broadband-ISDN and Asynchronous Transfer Mode (ATM) are the basis for international standards for future multimedia networks.
Synchronisation and orchestration
Synchronisation is the coordinated ordering of events in time. Synchronisation events have real-time deadlines, and the delay of transmission needs to be controlled. The variation in delay of transmission, referred to as jitter, must also be bounded. The interactivity and temporality of the multimedia services require that multimedia networks must provide low latency times and low jitter.
Orchestration is a meta-scheduling function where the different sub-systems, such as file system and network layer, are controlled as required by the applications [Koegel Buford, 1994, p.50].
Network should support variations in requirements by using Quality of Service (QoS) parameters for transmission. The agents should agree on the sufficient level of QoS taking application requirements and user preferences into account.
Multicasting
Even in personalised service architecture, the multicasting capability is required. The data should be transmitted simultaneously from one source to many destinations (for example live transmissions, or multiparticipant videoconferencing).
Figure 25. A protocol reference model for multimedia services [Sen, 1994, p.317]
Figure 25 is the broadband-ISDN model for implementing services appropriate for multimedia communications. These include media and session services [Sen, 1994, p.312].
Mediaware - media services
* Media Presentation. Access to distributed and multiple media information from heterogeneous end-user equipment. Media data format conversion among different representations for a given media type and multimedia data synchronisation to allow different types of media data to be presented with predefined spatial and temporal relationships.
* Media Control. Sharing and collaboration with multimedia information in multiuser communication. Support for composite data management mechanisms to compose documents consisting of different media. Dynamic updates for shared data to update changes in a multiparty session. Arbitration and access control of shared data.
Middleware - session services
* Session Control. Management and control of multipoint, multiuser, and multichannel connections.
* Advanced Data Exchange. Security and privacy control. Broadcasting and multicasting. Mobile agents and remote procedure calls. Deadlock avoidance mechanisms.
The most important scalability problems in the multimedia services are the network bandwidth and processor capacity of servers and clients. These scalability problems arise from three different causes [LaLiberte & Braverman, 1995, p.912]:
* Growth of the user base. Requests from users to random servers add to the network traffic in proportion to the number of requests, which is proportional to the number of users. This causes significant scalability problems for the network.
* Accessible data. The amount of accessible data is growing grapidly. Also the size of multimedia objects requires more capacity.
* Non-uniformity. The interests of users are never evenly distributed, so some servers are likely to experience more load than others.
Currently these problems are partly solved in the WWW by moving the data closer to the clients. This can be done either by caching or replicating the documents. If replicated servers are in clusters near to the original server the load on the server is reduced. However, this does not reduce the network traffic because all requests still go to the same cluster. If the data is replicated to servers around the network, and if clients can automatically locate the nearest server, the network traffic would also be reduced.
A hierarchical caching model (see figure 26) is needed for multimedia services. Multimedia servers of suitable storage, processing and network capabilities could be organised in a multi-level configuration to replicate the material closer to the customers. Content providers try to implement optimisation of their resources by combining the transmissions of different customers, and caching the material as the requests from different users are known.
Figure 26. Hierarchical caching model
The content producers may serve the material directly to the customers. In practise, most of the resources needed for propagating the material to the user (network bandwidth, storage facilities) will be provided by the network operators and other specialised companies. Under this metropolitan level there could be an organisational and neighbourhood level. The geographical hierarchy is not necessarily the right model, since an ATM-based WAN connection is much faster than a standard Ethernet LAN connection. The hierarchy should be based on available bandwidth.
Does the mobile agent-based approach to transactions scale? The asynchronous nature of mobile agents appears likely to enable high transaction rates between servers. On the other hand, the need to execute the agents and to support rigorous security around the agent execution environment could result in significant computational load. The following example illustrates this concept [Harrison, 1995]:
How many agents would Dow Jones wish to support on its stock price server? Is it plausible that hundreds of thousands of agents sit there monitoring the ticker feed? Dow Jones may wish to sell the computational capacity to support the load, or alternatively, third-party servers, which receive the ticker feed from Dow Jones, may offer this as a value-added service. If Dow Jones can charge for the service of hosting the resident agents, this may be an interesting service business in itself.
Agent-oriented programming, or agentware, is based on software languages and tools that are used to create programs that interoperate in a heterogeneous environment, and exchange information and services with other programs. Using this agent-based software engineering approach, the application programs are written as software agents that communicate with their peers by exchanging messages in an expressive communication language [Genesereth & Ketchpel, 1994, p.49].
In this chapter, four different approaches for building agent-enabled software are presented: KQML[19], Safe-Tcl[20], Java[21], and Telescript[22]. Many important technological issues are to be resolved before widely adopted distributed agent systems are possible:
* what is an appropriate agent communication language?
* does the agent execution require significant computational resources?
* does the use of mobile agents result in more or less network traffic than alternate methods?
* how to design an interoperable infrastructure and set of protocols to make it all work portably?
* how to make the system safe by limiting the scope, access and effect of any malevolent code?
* how does the agent protocol support networked multimedia applications?
The notion of an agent as a self-contained, concurrently executing software process, that encapsulates some state and is able to communicate with other agents, can be seen as a natural development of the object-oriented programming paradigm. There are thus many similarities between agent-oriented programming and distributed object architectures, such as CORBA[23] or OpenDoc[24]. Like an object, an agent provides a message-based interface, which is independent of its internal structures and algorithms. In an agent communication language, the meaning of a message should have a common interpretation in all agent implementations.
The emerging agent communication languages can be divided in three categories: procedural, object-oriented and declarative languages. Of the agentware considered in this section, Safe-Tcl is procedural, Java and Telescript are object-oriented and KQML is declarative.
ARPA Knowledge Sharing Effort is a consortium that develops conventions facilitating sharing and reuse of large-scale knowledge bases and knowledge-based systems. The researchers in this consortium has defined the Agent Communication Language (ACL), that is a declarative language based on the idea that communication between agents can be best modeled as the exchange of message containing declarative statements (for example, definitions, assumptions).
Communication takes place on several levels:
* content of the message
* locating and engaging the attention of another agent
* packaging a message in a way that makes clear the purpose of an agent's communication
ACL consists of three parts - its vocabulary, an "inner language" called KIF (Knowledge Interchange Format), and an "outer language" called KQML (Knowledge Query and Manipulation Language). An ACL message is a KQML expression in which the "arguments" are terms or sentences in KIF formed from words in the ACL vocabulary [Genesereth, 1994, p.49]. The vocabulary of ACL is listed in a dictionary of words appropriate to common application areas.
KIF is a prefix version of the language of first-order predicate calculus with extensions to enhance its expressiveness. It provides for the encoding of data, constraints, negations, disjunctions, rules, quantified expressions, metalevel information, and so forth. However, in the context of this thesis, the concept of KQML is more interesting.
When using KQML, a software agent transmits content messages wrapped inside a KQML message. The content message can be expressed in any representation language and be written in either ASCII strings or in binary notation. KQML implementations ignore the content portion of a message except to recognise where it begins and ends.
The syntax of KQML is based on a balanced-parenthesis list (Lisp-like notation). The initial element of the list is the performative and the remaining elements are the performative's arguments as keyword/value pairs.
KQML is expected to be supported by software that makes it possible for agents to locate one another in a distributed environment. These mediator programs are commonly called routers or facilitators. One such implementation is the Agent Name Server for TCP environment. The helper environments are not part of the KQML specification. Most of the current KQML environments will evolve to use one or more of the emerging commercial frameworks, such as CORBA or OLE [Mayfield, 1995].
The KQML language simplifies its implementation by allowing KQML messages to carry any useful information, such as the names and addresses of the sending and receiving agents, a unique message identifier, and notations by any intervening agents. There are also optional features of the KQML language which contain metadata descriptions of its content: its language, the ontology[25] it assumes, and some type of more general description. These features make it possible for supporting environments to analyse, route and deliver messages based on their content, even though the content itself is inaccessible.
The set of performatives forms the core of the language. It determines the kinds of interactions one can have with a KQML-speaking agent. The primary function of the performatives is to identify the protocol to be used to deliver the message and to specify if the content of the message is an assertion, a query, or a command. They also describe how the sender would like any reply to be delivered.
The reserved performatives fall in seven basic categories:
* basic query (evaluate, ask-if, ask-in, ask-one, ask-all)
* multi-response query (stream-in, stream-all)
* response (reply, sorry)
* generic informational performatives (tell, achieve, cancel)
* generator performatives (standby, ready, next, rest, discard)
* capability-definition (advertise, subscribe, monitor, import, export)
* networking (register, unregister, forward, broadcast, route)
Conceptually, a KQML message consists of a performative, its associated arguments which include the real content of the message, and a set of optional transport arguments, which describe the content and perhaps the sender and receiver. Each message in KQML is a piece of a dialogue between sender and receiver.
KQML-speaking agents can communicate directly with other agents by addressing them by their symbolic name, broadcast their messages or solicit the services of fellow agents or facilitators for the delivery of a message by using appropriate performatives.
Here is an example of a KQML message:
(tell :content "father(John, Alice)" :language prolog :ontology Genealogy :sender Gen-1 :receiver Gen-DB)
The performative tell is used to send an expression in Prolog from agent "Gen-1" to another agent "Gen-DB". The ontology named "Genealogy" may provide additional information regarding the interpretation of the content.
A message representing a query about the price of a share of Nokia stock at the New York Stock Exchange (NYSE) might be encoded as:
(ask-one : content "price(NOKIA, [?price, ?time])" : receiver stock-server : language standard_prolog : ontology NYSE-TICKS)
KQML contains also performatives related to capability definition, such as advertise, which allows an agent to announce what kinds of asynchronous messages it is willing to handle, and recruit, which can be used to find suitable agents for particular types of messages. For example the NYSE server might have earlier announced:
(advertise : ontology NYSE-TICKS : language standard_prolog : content (monitor : content "price (?x, [?price, ?time])"))
This means that the agent announces that it is a stock ticker and invites monitor requests concerning stock prices. New client agents can subscribe to the service and monitor the information stream:
(monitor : content "price (NOKIA, [?price, ?time])")
The current implementations of KQML API are available for C, C++, Prolog and Lisp. KQML can use many different transport protocols (HTTP, SMTP, TCP/IP, etc.). KQML has been mostly used for industrial automation applications, most importantly at Lockheed Missiles and Space Company, Inc. Lately, there has been many other types of emerging KQML applications.
The Personal News Assistant system employs KQML for message transport and communication among agents and the article search server. The KAPI (KQML API) library, that provides an interface into C and C++ languages, has been used. The main advantages for using KQML has been the ability to address the agents by their symbolic names using Agent Name Sever, and the ability to transfer messages in different transport protocols (TCP/IP sockets, email, HTTP). Overall, KQML seems a promising approach for building systems with agent-to-agent intercommunication.
Tcl (Tool Command Language)[26] is a public domain language widely used in the Internet community. Since Tcl was developed as a flexible, machine-independent scripting language, it also serves as a good foundation for building agent-based applications on the Internet. Safe-Tcl[27] is an Tcl extension, that was originally developed to build an enhanced electronic mail system, where the incoming message could be a Tcl script that the recipient executes in a safe mode. The script would display data on the screen and perhaps add functional buttons and other GUI devices, run distributed forms, surveys and other interactive services.
The syntax of Safe-Tcl is identical to the syntax of Tcl. The differences between Tcl and Safe-Tcl are in the set of available primitive functions and procedures. "Dangerous" primitives that control files, memory or processes in Tcl have been removed, while certain new primitives have been added. Some of these are available to all Safe-Tcl programs, while others are available only with certain values of the evaluation-time parameter or in certain user interface environments.
The Safe-Tcl has a simple structure. The normal Tcl is distributed as libraries that build a small interpreter for the language. An interpreter is linked into the program code, and it executes the code for controlling the basic tools built in the script. Each tool responds to some of its own Tcl commands, and the scripting language is responsible for executing the code and sending off the commands to the tools.
There are two interpreters in Safe-Tcl. The normal-mode Tcl can access tools that do things like reading and writing files, peeking and poking memory, or starting and stopping processes. The Safe-Tcl interpreter can't access those tools and acts as a barrier to keep unauthorised agents from vital host components. Information passes between the two interpreters as procedure calls.
Figure 27. The structure of Safe-Tcl
To create an information server that would respond to particular queries, tools for answering the queries would run in the normal Tcl interpreter. Then the incoming agent would be allowed to use a limited set of instructions available in its protected space. Protection against infinite loops or time-wasting agents exist in the time management functions of the Tcl interpreter running the agent. This evaluator checks the time used by the agent before instruction is interpreted and executed.
Here is a brief agent application that is evaluated during the activation time:
Content-Type: application/safe-tcl; evaluation-time=activation proc ordershirt {} { SafeTcl_sendmessage -to tshirts@otaonline.hut.fi\ -subject "T-shirt request" \ -body [SafeTcl_makebody "text/plain" \ [SafeTcl_getline \ "What size t-shirt do you wear?" \ "medium"] "" ] exit } set foo [mkwindow] message $foo.m -aspect 1000 \ -text "Click below if you want an OtaOnline T-shirt!" button $foo.b -text "Click here for free shirt!" \ -command {ordershirt} button $foo.b2 -text "Click here to exit without ordering" \ -command exit pack append $foo $foo.m {pady 20} $foo.b {pady 20} \ $foo.b2 {pady 20} exit
HotJava is a WWW browser by Sun Microsystems that is built using a new language called Java. HotJava expands the Internet browsing techniques by implementing the capability to add arbitrary behavior, which transforms static data into dynamic applications.
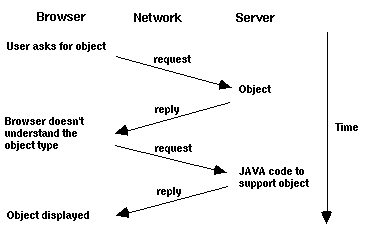
Figure 28. Dynamic HotJava functionality
HotJava provides a way for users to access applications by transparently migrating them across the network. Content providers don't have to worry about whether some special piece of software is installed in a user's system, it is transported as a HotJava applet[28] when needed.
One can think of Java language as a simplified, safe, and portable version of C++. It has an architecture-neutral virtual machine format, meaning that compiled Java code runs on most CPU architectures.
A simple "Hello world!" applet in Java code looks as follows:
import browser.Applet; import awt.Graphics; class HelloWorld extends Applet { public void init() { resize(150,25); } public void paint(Graphics g) { g.drawString("Hello world!", 50, 25); } }
The HTML-file that includes this applet could look like this:
<HTML> <HEAD> <TITLE> A Simple Program </TITLE> </HEAD> <BODY> Here is the output of my program: <APP CLASS="HelloWorld"> </BODY> </HTML>
HotJava enables the content provider to export programs across the net and to execute them at the client-side. However, moving programs across the network, installing, and running them is an open invitation to security problems. The security in HotJava is based on interlocking layers of security that range from the design of the Java language at the base to the file and network access protections at the top. These layers are [Sun, 1995]:
* The Java language, which was designed to be a safe language and the Java compiler which ensures that source code doesn't violate the safety rules.
* A verification of the byte codes imported into the runtime to ensure that they obey the language's safety rules. This layer guards against an altered compiler producing code that violates the safety rules.
* A class loader which ensures that classes don't violate name space or access restrictions when they are loaded.
* Interface-specific security that prevents applets from doing destructive things. It depends on the security guarantees of the previous layers. This layer depends on the integrity guarantees from the other three layers.
WWW is a good example of what can be achieved in two years by providing and disseminating a standard information server (HTTP server) and clients. The HTTP protocol has become so popular that further progress in making information available via the Internet is only discussed in terms of extensions to Web servers and clients. Sun's HotJava is the first example of an experiment to provide mobile agent extensions to the Web. The popularity of Sun's approach remains to be seen, but it has potential to be successful and be deployed very quickly on a large number of servers and clients.
In late 1994, AT&T introduced the first commercially available agent-based wide-area network, called PersonaLink. PersonaLink is designed to be a distributed and scalable applications environment, through which third-party content and service providers can deliver news information, entertainment, and electronic shopping. PersonaLink is designed to support multimedia message types and it supports intelligent routing and smart mailboxes. PersonaLink runs only on AT&T's dedicated network infrastructure.
The foundation of PersonaLink is the General Magic Inc.'s Telescript technology and Magic Cap operating system. The Magic Cap software running on Sony and Motorola PDAs consists of a Telescript Engine, a GUI and communications modules.
General Magic's vision is that users will send executable programs in form of software agents into networks, telling them what information or services they are looking for and how much they want to spend, then wait for them to return with the results. Telescript agents can perform many personalised functions, from filtering electronic mail to shopping for goods and information on users behalf. To execute such tasks, Telescript agents can cooperate with other agents, clone themselves when needed and be customised by users.
Telescript technology consists of four main components: language, engine, protocol set, and applications.
* Telescript language is designed for carrying out complex communications tasks: navigation, transportation, authentication, access control, etc. [White, 1994]. The language is a pure object-oriented language.
* Telescript engine acts as an interpreter for the Telescript language, maintains places, schedules agents for execution, manages communication and agent transport, and finally, provides an interface with other applications.
* Telescript protocol set deals primarily with the encoding and decoding of agents, to support transport between places. The network of interworking Telescript Engines provides an abstract homogeneous environment in which to build distributed systems.
* Telescript applications are developed with a set of software tools specifically designed for this task.
All the data and the processes in Telescript are objects and part of the basic object hierarchy. Telescript is interpreted language, and this provides much of its security. Each incoming agent can access only its own objects or other explicitly specified objects. The agent can't write to the system memory or to the disk. Each Telescript agent has an identity that is cryptographically authenticated and encrypted using a RSA-based algorithm.
The foundation class of Telescript's object hierarchy is the process. This is an object with a packet of code, data objects, a stack, and an instruction pointer. The Telescript engine on each network runs multiple processes and pre-emptively switches between them. Thus one engine is able to host multiple agents that swap data and information.
Two other key concepts in Telescript technology are places and agents. A place is a unique network address that is the metaphorical gathering point for agents. Together these objects represent a virtual space in which other objects can interwork. Each Telescript engine can support a number of places. Agents are the providers and consumers of goods in the electronic marketplace applications.
In the figure 29, an example scenario is presented. The outside agent is executing a Telescript application to "go to place 130.233.192.48 to receive an electronic payment". The local agent is told to "meet at place 130.233.192.1 to swap sales statistics".
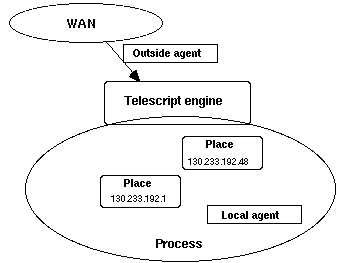
Figure 29. Telescript functionality and important classes [Wayner, 1995]
Places provide meeting locations for agents. At a place, agents can exchange information and perform computation. Agents are able to move from one place to another, in which case their program and state are encoded and transmitted across the network to another place, where execution recommences. Agents are able to communicate with one-another: if they occupy different place, then they can connect across the network; if they occupy the same location, then they can meet one another.
An agent transports itself from one place to another place on a different engine using the go method. The execution of the agent is suspended, its state information encoded and transferred through the communications medium, then decoded, and finally the agent's execution is resumed at the new location.
Agents have attributes such as identity and owning authority which uniquely identify the agent and the entity responsible for it. These attributes may be used for authentication and authorisation.
The agent's ability to pay for services is measured in Teleclicks, the electronic currency of Telescript architecture. During execution of the agent by the server, the server is entitled to transfer Teleclicks from the agent to the agent execution environment as a form of payment. Telescript objects have a permit attribute which may be used to limit the amount of resources which the agents may consume, for example a place may ask an agent to pay it 30 Teleclicks before granting it access to some resource. A secure permit feature is crucial to stop agents from creating clones of themselves, exhausting resources, or other such anti-social behaviour [White, 1994].
Of the agent-enabling tools considered in this thesis, Telescript is the closest implementation of the electronic marketplace concept introduced in chapter 2. However, Telescript is not likely to be widely adopted in its current AT&T operated form. Many of the ideas in the Telescript framework are likely to be introduced in the Internet in the near future.
This chapter recommends potential personalised multimedia applications to be implemented in the context of OtaOnline project: personal OtaOnline news agent and agent-mediated advertising.
One of the original ideas of the OtaOnline project was to "clone" the Fishwrap-project at MIT Media Lab to the Otaniemi environment using Aamulehti Group's articles as contents. Fishwrap is a fully personalised news service, that relies on full-text search and keyword-based profiles updated manually by the readers. The personalised service model was soon considered a side-track in the OtaOnline project as it became clear that the editorial process will be an important part of the networked multimedia production.
To complement the editorial approach, I propose that the OtaOnline product will be extended with "Your personal OtaOnline". Agent technology is used to provide each user their own personalised version of material available in connection with OtaOnline. There will be an additional section in the OtaOnline, where a user can browse the news items his agent has selected. This would allow us to:
* introduce a new dimension to OtaOnline as a product
* use interesting new filtering techniques, especially social information filtering
* test the collaborative rating systems
* compare the usage of edited and automated news services side-by-side
When the instrumentation tools and database modeling are available in the OtaOnline project, the personalised version can be produced for each OtaOnline user. Also the OtaOnline's future access to Aamulehti archives increases considerably the volume of available material, so the personalised service can really be interesting from consumer perspective.
Each OtaOnline user has a possibility to start using a consumer agent for information filtering - InfoMediator. This information filtering agent is capable of modeling the user's interests in a user profile and sending information requests to OtaOnline producer agent. OtaOnline's agent includes Media Object Brokers (MOBs) that promote the information available on their server to InfoMediators.
The system will use content-based filtering and social filtering techniques. The service is mostly based on keyword searches of user-specified topics, but the agents can also send recommendations to each other. A simple price negotiation model between the agents can also be implemented. The service provider can have fixed rates for different levels of service and the consumer agent will be notified about the price.
This work can be based on the prototype system already built in the Personal News Assistant project. Figure 30 shows an example of the current user interface for profile editing. The current version of this system has limited features, and the learning and user interface modules must be enhanced. The system uses KQML messaging for agent intercommunication.
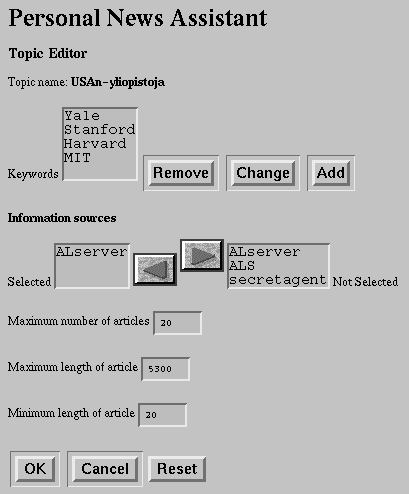
Figure 30. Personal News Assistant's topic editor
It is realistic to assume that this system can be implemented in three man-months, given that we can use Personal News Assistant as a basis for this work.
In electronic commerce, the consumer should not be locked into dealing with a particular producer. Today the electronic market is still rather closed: the consumer can access only those producers supported by a particular service and the producer can reach only those consumers subscribed to the service. This market model is rapidly giving way to "open" or unbiased electronic marketplace in which consumers and producers engage in direct and spontaneous commerce. Obstacles for more rapid evolution of this open marketplace are:
* the difficulties consumers and producers have in finding each other
* lack of common transaction protocol or the ability of the user to easily acquire the producer's proprietary application protocol
* lack of privacy and security, although producers appear willing to perform experiments without thoroughly solving these problems
Agents offer a number of useful possibilities for electronic commerce:
* The consumer agent is able to present the consumer's desire as a query to a number of potential vendors to determine degree of match, price, availability, and so forth. The user preferences are taken into account in filtering the material.
* The producer agent can advertise its services to consumer agents.
* The user can be presented with a customised user interface, for example a virtual mall, that can be tailored to meet user preferences.
* The consumer agent may be able to consult a "consumer guide" or other advisor before making a purchase.
* The producer agent can express the application-level protocol, that is required to perform a transaction, in a device independent way. This includes dialogues on choices and options, configurations, availability, delivery methods, opportunities for selling up and so forth.
* The producer agent can provide a secure vehicle for the transaction, providing bilateral authentication and privacy. The agents can use a transaction currency for settlements; the agents' accounts are reconciled periodically against "real" money.
We can also anticipate a wide range of secondary commercial or quasi-legal services, such as brokers and inspectors, in support of electronic consumerism.
The role of advertising is unknown to a large extent in the future of electronic markets. Currently, advertising pays for a significant amount of the contents in broadcast and newspaper media. If the end-user is given a customisable service with the ability to skip all the commercials, advertisers may not be so keen on sponsoring this new technology. This suggests that there is a new place for advertising in the world of interactive multimedia commerce, some kind of "commercials-on-demand" service. Filtering techniques can be used to screen advertising messages and product descriptions according to precisely the criteria that are important to a given customer. Advertisements could also be appropriate material for economic information filtering.
Advertising is a promising application domain for social information filtering. Currently companies spend a lot of resources in making demographic studies in order to direct advertising. Social information filtering automates this process, and marketing can be directed to a small but potentially interested group of individuals.
The reasons for providing customised advertising service in the OtaOnline are:
* learn to use the agent technology for information brokering
* try the advertisement brokering concept in OtaOnline testbed
* use the metadata approach to advertising
* try economic filtering approach for advertisements
* learn how the contents of the advertisements can be personalised
* find out the user reactions to personalised advertising
The advertisers could find the interested users directly without OtaOnline. The role of the OtaOnline product in personalised advertising application is to provide for the advertisers a gateway to the consumers. The personalised advertising is part of the OtaOnline service concept, that the user is accustomed to. Also there is plenty of advertising material that are currently printed and that can be used directly in this experiment. The new skills required are coding of agent-understandable descriptions of the contents of the advertisements and the capacity to store and distribute the advertising agents to the customers.
The widespread use of distributed information services will radically alter the way in which both organisations and individuals work. There are many indicators of this coming information revolution. The growth of network technology, the routine use of email within commercial organisations, and the astonishing extent of interest in the World-Wide Web are three obvious examples.
While the enormous potential presented by distributed information services is widely recognised, the software required to fully realise this potential is not yet available. Most importantly, the current software paradigms simply do not lend themselves to developing the kind of applications required. In order to build computer systems that must operate in large, open, distributed, highly heterogeneous environments, we must make use of entirely new software technologies.
The concept of an intelligent agent, that can operate autonomously and rationally on behalf of its user in complex network environments, is increasingly promoted as the foundation upon which to construct such a technology. The ability of agents to autonomously plan and pursue their actions and goals, to co-operate, co-ordinate, and negotiate with others, and to respond flexibly and intelligently to dynamic and unpredictable situations will lead to significant improvements in the quality and sophistication of the software systems that can be conceived and implemented, and the application areas and problems which can be addressed.
There are many possibilities for creating personalised services in a network environment. Consumers have different needs and tastes, different habits, and different equipment and bandwidth to access the services. The role of the intelligent agents is to act as electronic brokers, and to match the needs of the consumers with the available producers in the information marketplace.
An information filtering agent should be able to do sophisticated semantic retrieval of information objects from a multimedia object database. The consumer agent makes a query to one or more producer agents at the servers, which retrieve information and present it to the consumer agent, possibly getting additional feedback on the query and quality of the information retrieved.
The ideal system will possess knowledge specific to the domain in which it operates and specific to the user's interests, as well as the ability to filter data based on this knowledge. It is more efficient for the program extracting this knowledge to go to the source of the data instead of sending the data to the program, especially since the program is primarily filtering and summarising the data. It might also identify documents potentially interesting to other agents and inform them of this fact. Distributed intelligent agents, which are co-resident with the data sources have an advantage over centralised, more static systems.
Agent technology can be expected to appeal strongly to the Internet community, since it can solve the problems of finding services and information and since it empowers the individual user. First agent-enabling extensions to the World-Wide Web protocols, most notably HotJava, have already been introduced.
The architecture presented in this work introduced the main components and problem areas in the creation of personalised multimedia services. Many of the services proposed in this work are feasible in a limited test environment already today. However, gigabit networks, more efficient CPUs, real-time operating systems, and enormous storage facilities are needed to satisfy the requirements for large-scale personalised multimedia applications.
Literature
Alexander G.A. (1995). Getting the World-Wide Web Ready for Business Applications. The Seybold Report on Desktop Publishing, volume 9, number 7, page 3
Belkin N. J., Croft W.B. (1992). Information Filtering and Information Retrieval: Two Sides of the Same Coin. Communications of the ACM, December 1992, volume 35, number 12, pages 29-38
Bowman C.M., Danzig P.B., Hardy D.R., Manber U., Schwartz M.F. (1994). The Harvest Information Discovery and Access System. In "The Second International WWW Conference '94. Advance Proceedings", pages 763-771
Carl-Mitchell S., Quarterman J.S. (1995). How big is the Internet? Matrix News, 5(1), January 1995. Matrix Information and Directory Services, Inc. (MIDS), 1106 Clayton Lane, Suite 500W, Austin, TX 78723, U.S.A.
Clark J. (1992). A TeleComputer. Computer Graphics, July 1992, volume 26, number 2, ACM Press, pages 19-23
Commission of the European Communities (1993). New Opportunities for Publishers in the Information Services Market (Executive Summary). Report EUR 14295 EN, ECSC-EEC-EAEC, Brussels - Luxembourg
de Kleer J., Forbus K., McAllester D. (1989). Truth Maintainance Systems, Tutorial. IJCAI'89: 11th International Joint Conference on Artificial Intelligence. Detroit, U.S.A., pages 1-375
Denning P. (1982). Electronic junk. Communications of the ACM, March 1982, volume 25, number 3, pages 163-165
Etzioni O., Lesh N., Segal R. (1994). Building softbots for UNIX. In "Software Agents - Papers from the 1994 Spring Symposium (Technical Report SS-94-03)", AAAI Press, pages 9-16
Foner L. (1995). What's an agent - anyway? MIT Media Lab, Cambridge, MA, U.S.A.
URL http://foner.www.media.mit.edu/people/foner/Julia/
Furht B. (1994). Multimedia Systems: An Overview. IEEE Multimedia, Volume 1, Number 1, pages 47-59
Genesereth M.R., Ketchpel S.P. (1994). Software Agents. Communications of the ACM, July 1994, volume 37, number 7, pages 48-53
Gibbs S.J., Tsichritzis D.C. (1995). Multimedia programming - Objects, environments and framework. ACM Press, Addison-Wesley, Padstow
Harrison C. G., Chess D. M., Kershenbaum A. (1995). Mobile agents: Are they a good idea? IBM Research Division. T.J. Watson Research Center, Yorktown Hights, NY, U.S.A.
URL http://www.research.ibm.com/xw-d953-mobag-ps
Hayes-Roth B. (1995). An architecture for adaptive intelligent systems. Artificial Intelligence 72, January 1995, Elsevier, pages 329-365
Hermes (1994). Results from the WWW Consumer Survey Pre-Test.
URL http://www.umich.edu/~sgupta/conres.html
Huang X., McCalla G.I., Greer J.E., Neufield E. (1991). Student model. User Modeling and User-Adapted Interaction 1. Kluwer Academic Publishers, Netherlands
Hämmäinen H., Eloranta E., Alasuvanto J. (1990). Distributed Form Management. ACM Transactions on Information Systems, volume 8, number 1, pages 50-76
Kay, A. (1990). On the next revolution. Byte, September 1990, volume 15, number 9, page 241
Koegel Buford J.F. (1994). Multimedia systems. ACM Press, Addison-Wesley, New York
Labrou Y., Finin T. (1994). A semantics approach for KQML - a general purpose communication language for software agents.
URL http://www.cs.umbc.edu/kqml/papers/kqml-semantics.ps
LaLiberte D., Braverman A. (1995). A protocol for scalable group and public annotations. In Computer networks and ISDN systems: Proceedings of the Third International World-Wide Web Conference, volume 27, number 6, Elsevier, pages 911-918
Little T.D.C., Venkatesh D. (1994). Prospects for Interactive Video-on-Demand. IEEE Multimedia, volume 1, number 3, Fall 1994, pages 14-24
Loeb S. (1992). Architecting Personalised Delivery of Multimedia Information. Communications of the ACM, December 1992, volume 35, number 12, pages 39-48
Maes P. (1994a). Agents that Reduce Work and Information Overload. Communications of the ACM, July 1994, volume 37, number 7, pages 30-40
Malone T. W., Grant K.R., Turbak F.A., Brobst S.A, Cohen M.D. (1987a). Intelligent information-sharing systems. Communications of the ACM, volume 30, number 5, pages 390-402
Malone T. W., Yates J., Benjamin R.I. (1987b). Electronic markets and electronic hierarchies. Communications of the ACM, volume 30, number 6, pages 484-497
Mayfield J., Labrou Y., Finin T. (1995) Desiderata for Agent Communication Languages. Proceedings of the AAAI Symposium on Information Gathering from Heterogeneous, Distributed Environments, AAAI-95 Spring Symposium, Stanford University, Stanford, CA
URL http://www.cs.umbc.edu/kqml/papers/desiderata-acl/root.html
McCarthy J. (1966). Information. Scientific American, September 1966, volume 215, number 1, pages 37-38
McLuhan M. (1964). Understanding Media. McGraw-Hill, New York, NY, U.S.A.
Mealling M. (1995). Encoding and Use of Uniform Resource Characteristics. IETF draft URL:ftp://cnri.reston.va.us/internet-drafts/draft-ietf-uri-urc-spec-00.txt
Miller M.S., Drexler E. (1988). Markets and computation: Agoric open systems. In "The Ecology of Computation", B.A. Huberman, Elsevier, pages 133-176
MIT Media Laboratory (1995). Media Laboratory Projects - February 1995. Communications and Sponsor Relations, MIT Media Lab, Cambridge, MA, U.S.A.
Mullen T., Wellman M.P. (1995). A Simple Computational Market for Network Information Services. AI Laboratory, University of Michigan, MI, U.S.A.
URL ftp://ftp.eecs.umich.edu/people/wellman/icmas95.ps.Z
Negroponte N. (1970). The Architecture Machine. The MIT Press, Cambridge, MA, U.S.A.
Orwant J. (1993). Doppelgänger goes to school: Machine Learning for User Modeling. MIT Media Laboratory, Cambridge, U.S.A. URL ftp://media.mit.edu/pub/orwant/doppelganger/
Papazoglou M.P., Laufman S.C., Sellis T.K. (1992). An organizational framework for cooperating intelligent information systems. Journal of Intelligent and Cooperative Information Systems, volume 1, number 1, pages 169-202
Pitkow J. (1995). GVU Center NSFNET Statistics.
http://www.cc.gatech.edu/gvu/stats/NSF/merit.html
Ramanathan S., Vengat Rangan P. (1994). Architectures for Personalized Multimedia. IEEE Multimedia, volume 1, number 1, pages 37-46
Reinhardt A. (1994). The Network with Smarts. Byte, October 1994, volume 19, number 10, pages 50-64
Resnick P., Zeckhauser R., Avery C. (1995). Roles for Electronic Brokers.
URL http://www-sloan.mit.edu/CCS/1994wp.html#CCSWP179
Resnick P., Iacovou N., Suchak M., Bergstrom P., Riedl J. (1994). GroupLens: An Open Architecture for Collaborative Filtering of Netnews. Proceedings of ACM 1994 Conference on Computer Supported Coopeartive Work, Chapel Hill, NC, pages 175-186
URL http://www-sloan.mit.edu/CCS/1994wp.html#CCSWP165
Roesler M., Hawkins D.T. (1994). Intelligent Agents. Online, July 1994, volume 18, number 4, pages 18-32
Shardanand U. (1994). Social Information Filtering for Music Recommendation. Master's thesis, MIT Media Laboratory, Cambridge, U.S.A.
URL http://shard.www.media.mit.edu/people/shard/ringo.ps
Shardanand U., Maes P. (1995). Social Information Filtering: Algorithms for Automating "Word of Mouth''. MIT Media Laboratory, Cambridge, U.S.A.
URL http://agents.www.media.mit.edu/groups/agents/papers/ringo/chi-95-paper.ps
Sheth B.D. (1994). A Learning Approach to Personalised Information Filtering. Master's thesis, MIT Media Laboratory, Cambridge, U.S.A.
URL http://agents.www.media.mit.edu/groups/agents/papers/newt-thesis/main.html
Shoham Y. (1993). Agent-oriented programming. Artificial Intelligence 60, Elsevier, pages 51-92
Stadnyk I., Kass R. (1992). Modeling User's Interests in Information Filters. Communications of the ACM, December 1992, volume 35, number 12, pages 49-50
Sun Microsystems Inc. (1995). HotJava: The Security Story.
URL http://java.sun.com/1.0alpha2/doc/security/security.html
Verkama M. (1994). Distributed methods and processes in games of incomplete information. Doctor's thesis, Systems Analysis Laboratory, Helsinki University of Techology, Research Report A55, TKK OFFSET, Otaniemi
Wayner P. (1995). Free Agents. Byte, March 1995, volume 20, number 3, pages 50-64
White J.E. (1994). Telescript technology: The foundation for the electronic marketplace. White paper, General Magic, Inc., 2465 Latham Street, Mountain View, CA 94040, U.S.A.
Wiederhold G. (1992). Mediators in the Architecture of Future Information Systems. Computer, March 1992, pages 38-49
Wieser M. (1993). Some Computer Science Issues in Ubiquitous Computing. Communications of the ACM, July 1993, volume 36, number 7, pages 74-84
Wooldridge M., Jennings N.R. (1995) Intelligent Agents: Theory and Practice.
URL ftp://ftp.elec.qmw.ac.uk/pub/keag/distributed-ai/publications/KE-REVIEW-95.ps.Z<>
Interviews
Maes P. (1994b). Assistant Professor of Media Arts and Sciences, MIT Media Laboratory. Cambridge, MA, U.S.A., 1994-10-17
Mauldin M. (1995). Research scientist, Carnegie Mellon University. Darmstadt, 1995-4-12
Sormunen E. (1994). Assistant Professor, Information Sciences Department, University of Tampere. Tampere, 1994-11-8
Sulonen R. (1995). Professor of Computing Science, Helsinki University of Technology. Various discussions
Ylinen M. (1994). Project Manager, Aamulehti Group. Tampere, 1994-11-8